6 System configuration
The following sections detail the more important aspects of configuring and using the main webservice, the command line and the static queue.
6.1 Main realtime endpoint
You PUT models and DELETE models on main webservice endpoint as shown in the basic planning walkthrough. The main endpoint is designed for realtime models. Models on the main endpoint will keep on optimising forever unless you DELETE them, or set them to autodelete.
When you PUT a new model to the main endpoint, ODL Live will calculate enough of the distances matrix to construct an initial solution, and then save the initial solution to the database. It will then continue optimising the model repeatedly in short bursts of a couple of seconds. As the initial solution has had very little optimisation time, it will be significantly sub-optimal, and will improve massively as ODL Live runs more optimisation bursts. You should therefore not use the first solution generated on the realtime endpoint as it hasn’t had much time to optimise. You can view graphs of solution cost (i.e. solution quality) versus optimisation time in the statistics page on the software developer’s dashboard.
If you have a ‘next-day’ type model, which you want ODL Live to optimise until it’s ‘ready’ (i.e. until ODL Live has a good solution), you should run the model on the command line or the static queue instead. The main endpoint is primarily designed for models that are left running constantly (e.g. realtime models).
6.1.1 RESTful endpoint conventions
The design of the endpoints mirrors the design of the objects and their hierarchy. Once you learn about the objects used by ODL Live, using the RESTful endpoints will be straightforward. There is one caveat however, some endpoints require a forward slash / on the end and some do not. If you’re doing GET or PUT on an array of objects (e.g. GPS traces in a vehicle), the endpoint should terminate in a forward slash /. If you’re doing GET or PUT on a single object (e.g. a vehicle, a job), the endpoint will not terminate in a forward slash.
6.1.2 Data syncing strategies for realtime
Your own IT system should act as the master data repository (i.e. the ‘single source of truth’), and you keep ODL Live in-sync with your data by pushing changes to it. The data you push to ODL Live is persisted in ODL Live’s own database, so it is preserved if the virtual server is rebooted.
The first step to using ODL Live is to construct a model object based on the data in your own system. Once constructed, use an HTTP PUT request to PUT the entire model. All PUT requests to ODL Live work as update-inserts (upserts) - if the object at the URL does not exist it is created and it does already exist it is replaced by the new version. PUT model will therefore create the model using the model id you specify in the PUT URL.
For many use cases, providing the JSON payload on your model is not massive, you can just recreate and resend the entire model whenever the data changes (e.g. new job). If the JSON is large or you find your database slowing down, you might want to consider incremental updating though. With incremental changes, you PUT new versions of jobs or vehicles as their state changes, instead of doing PUT for the whole model.
The recommending data syncing mechanism is therefore:
- PUT entire model to start with (using your own modelId in the PUT URL).
- If your model is smaller, PUT the whole model again whenever it changes.
- If your model is bigger:
- PUT or DELETE individual jobs and vehicles as changes happen to them
or their sub-objects (e.g. PUT a new version of the vehicle when a stop
arrival event occurs). This is subject to the caveats discussed in the
section on batching
updates.
- When deleting you have to be careful to ensure referential integrity - see later sections for details.
- Every X minutes, either (a) PUT all jobs and PUT all vehicles or (b) PUT whole model, to refresh all records.
- PUT or DELETE individual jobs and vehicles as changes happen to them
or their sub-objects (e.g. PUT a new version of the vehicle when a stop
arrival event occurs). This is subject to the caveats discussed in the
section on batching
updates.
By making smaller incremental changes immediately you can keep ODL Live’s data up-to-date whilst still only sending small objects (which helps preserve bandwidth and minimise data transfer costs). If you refresh all data every once-in-a-while, if the data in ODL Live somehow became out-of-sync with your master data, this would be corrected when the refresh happens.
If hosting on AWS (or another cloud provider which charges for the amount of data written), you are advised to monitor your data transfer costs.
6.1.2.1 Batching updates
In some circumstances you may need to batch updates to ODL Live, to get best performance. This is a result of the way the system operates, in particular:
ODL Live will process multiple writes to a single model sequentially, not in-parallel. Multiple writes to the same model will queue and be processed one-at-a-time.
The backend database stores jobs and vehicles atomically. A write to a sub-object within a vehicle (e.g. a new stop completed event) will still cause the entire vehicle object to be sent from the optimiser server to the database server (and same for jobs).
Thus there is no performance benefit to writing sub-objects to a job/vehicle instead of replacing the whole job/vehicle and in-fact this may create performance issues, due to write queueing within a model. If you have multiple pending writes to a model (e.g. 5 different vehicles changes), it is beneficial to batch them otherwise these writes will queue and be executed sequentially. The following batch writes are available:
PATCH. Send an updated subset of jobs and/or vehicles, see PATCH section for example.
PUT all jobs
PUT all vehicles
PUT whole model
For an individual model, you should do a maximum of one or two PUTs every couple of seconds, or writes will start to queue. For GPS trace updates it may therefore be beneficial to do a PUT all vehicles every 10 seconds or minute (for example), or do a PATCH where you update the X most out-of-date vehicles every Y seconds. The system assumes that the vehicle continues driving after its last GPS update and will extrapolate its current position, so only updating GPS positions every minute will not have a large impact on optimiser accuracy.
If you start to get timeouts or slow responses to your HTTP PUT requests, this is a sign that you’re pushing too much data too often to the server and you should send PUTs less often. The optimiser and database servers themselves will only be able to process a finite amount of write requests per second over all models too - although we can size these servers up according to your incoming data rate if needed.
6.1.3 Auto-deleting a model after a certain datetime
You can set a model to be automatically deleted from the ODL Live system at a certain datetime. This is useful if you have a different model for different days and want to delete the model at the end of the day, so it no longer consumes ODL Live resources (e.g. CPU, memory).
To set a model to be automatically deleted, set the deletion time in UTC to the field model.configuration.deleteModelAfter, as shown in the following JSON:
{
"data" : {
"jobs" : [
...
],
"vehicles" : [
...
]
},
"configuration" : {
"distances" : {
...
},
"deleteModelAfter" : "2020-01-20T23:59"
},
"_id" : "Model1"
}6.1.4 PATCH model
A PATCH endpoint is available which can update a subset of the model (e.g. update one or more jobs or vehicles at once). The PATCH has two main functions, (1) updating jobs or vehicles and (2) updating many vehicle GPS locations at once, without having to include the vehicle object itself (remember the GPS trace is a subobject within the vehicle object).
6.1.4.1 PATCH for jobs and vehicles
If you’re using the PATCH to update jobs or vehicles, you should send an object with the following structure:
{
"jobs" : [
{
... job 1 data including id...,
},
{
... job 2 data...,
}
],
"vehicles" : [
{
... vehicle 1 data including id...,
},
{
... vehicle 2 data ...,
}
]
}where each job and vehicle object contains its normal data including its ID. The structure of this patch JSON is identical to the data object in the model object you’ve encountered in the other chapters of this guide, except you’re only sending a subset of the objects. The objects you don’t send will remain unchanged on the server. Send to the following URL using HTTP PATCH:
PATCH my-base-URL/models/my-model-id/datawhere you replace my-base-URL with the one provided to you.
6.1.4.2 PATCH for many GPS locations
The following JSON shows an example of using the PATCH endpoint to update vehicle GPS locations:
{
"jobs" : [ ],
"vehicles" : [ ],
"currentGPSByVehId" : {
"V0" : {
"time" : "2019-10-30T07:57:10.251",
"coordinate" : {
"latitude" : 0.0,
"longitude" : 0.0
},
"type" : "GPS_DEVICE",
"_id" : "zFXOQr5jRIOCqdUnHNjdng=="
},
"V1" : {
"time" : "2019-10-30T07:57:10.651",
"coordinate" : {
"latitude" : 1.0,
"longitude" : 1.0
},
"type" : "GPS_DEVICE",
"_id" : "R1_pB5brS16SGtRGhh9Akg=="
}
}
}currentGPSByVehId is a map where the key is the vehicle id and the value is the latest trace object. This trace object replaces the array of trace objects on the vehicle (i.e. sets an array of length 1, as you only ever need the current GPS). If currentGPSByVehId is non-empty, the vehicles list must be empty or it will throw an error. Note that if you spell currentGPSByVehId incorrectly or get the vehicle ids wrong (e.g. ‘v0’ instead of ‘V0’) the PATCH will fail silently and your GPS records will not be updated.
You don’t need to update GPS on all vehicles in the call, you can just update a subset if you want to. This call locks all writes to the model while it executes. As you don’t need to include the vehicle object just to update the GPS, the locking ensures there’s no danger of overriding the vehicle with an old version of a vehicle object when you send the data.
Internally this call reads all vehicle records from the database (in a single query) as the first part of its execution, so it should not be used to update the GPS for only one or two vehicles at-a-time, as this will be cause performance issues.
6.2 Static queue
A ‘static’ routing model is a non-realtime model, e.g. for planning next-day routes instead of same-day. The static model queue lets you PUT a static model to ODL Live, where it gets optimised for a maximum amount of time, then finishes optimising and ODL Live stores the result. You can PUT many static models to the queue and they are processed in a first come, first served order.
If you’re a self-hosting subscriber, you can also run static models on the command line API, which is more suitable for larger models and for serverless cloud computing enviroments.
The static queue is a suitable solution when you have many non-realtime / static models and you want to process them all in-order until they’re ‘finished’. This is different to ODL Live’s normal mode. By default ODL Live is a realtime-first optimiser, so it’s designed to keep multiple realtime routing models up-to-date at the same time. In default mode, it never decides that a model is finished and will always keep processing it.
If using webapp1, only use the static queue for smaller problems. In webapp1, a static queue model will only use one thread when optimising, so the static queue is not recommended for very large models (e.g. over one thousand jobs) if you’re using webapp1. In webapp1, large problems with thousands of jobs could also have issues with not enough memory when they are run on the static queue, instead of being run as a normal live model. When running models on the command line instead, you can set them to use as many threads as you want. When running static models on webapp2, the optimiser automatically takes care of thread management and will multi-thread where appropriate.
6.2.1 Configuring your model JSON for the static queue
The models you send to the static queue have exactly the same structure as normal realtime models, the only exception being that you should include an extra object in the configuration to let the static queue know how long it should run the model for. You should still set timeOverride as well, unless you’re optimising jobs and vehicles for future dates (see section on time override for more details).
Setting maximum runtime for a static queue model. When you leave ODL Live to optimise for longer, it finds better solutions. Generally it finds the big cost improvements early-on and only finds small cost improvements later. Technically speaking, the cost of the solution vs optimisation time exhibits exponential decay, like in the following graph:
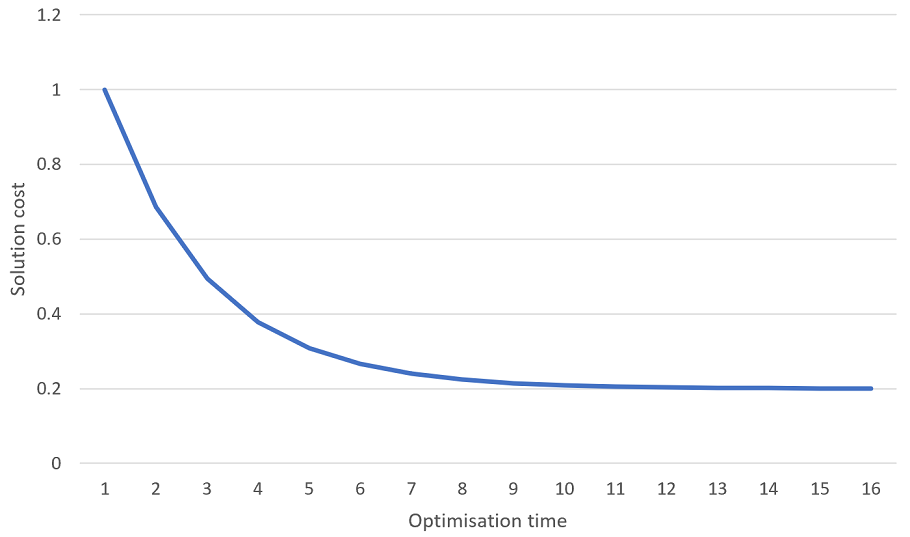
This means that even after optimising for a long time, ODL Live can still sometimes find better solutions, but these solutions are generally only a tiny bit better (e.g. 0.0001% savings on travel). As optimisation never really ‘finishes’, we have to give ODL Live rules which specify when it should stop optimising.
The object which tells the static queue when to finish optimising a model is found in:
model.configuration.staticCPUBudgetIn the following example, we setup a model which will optimise for no more than 10 minutes (600000 milliseconds) and will finish early if we don’t find an improvement to the current solution for 3 or more minutes (180000 milliseconds):
{
"data" : {
"jobs" : [ ... ],
"vehicles" : [ ... ]
},
"configuration" : {
"distances" : {
...
},
"staticCPUBudget" : {
"maxMillis" : 600000,
"maxMillisWithoutImprovement" : 180000
}
},
"_id" : "myModelId"
}The object staticCPUBudget has the following fields:
- minIterations
- maxIterations
- maxMillis
- maxIterationsWithoutImprovement
- maxMillisWithoutImprovement
The optimiser will perform the minimum number of iterations (minIterations) and then it will keep on optimising until it hits the first one of the following exit conditions:
maxIterations, the optimiser has done the maximum number of iterations.
maxMillis, the optimiser has been running for the maximum amount of milliseconds.
maxIterationsWithoutImprovement, the maximum number of iterations without improvement has been hit.
maxMillisWithoutImprovement, the optimiser has been running for the maximum number of milliseconds without improvement.
Webhooks. Although it’s simpler to keep on polling for the plan being ready, you can also use the webhooks functionality to call back to your system when the plan is ready. See section on webhooks for more details.
6.2.2 Using the static queue
To use the static model queue, after modifying your application.yml and restarting Tomcat (webapp1 only), you can PUT a static model to the queue using the endpoint:
PUT my-base-URL/modeltypes/queuedstatic/myModelIdYou should ensure your model id (‘myModelId’ in our example) is unique. The static queue will start optimising this model when a static queue thread becomes available, after processing all other static models which were already queued (i.e. first-come-first-served). When your model is ready, the plan will be available at:
GET my-base-URL/modeltypes/completedstatic/myModelId/optimiserstate/planSimply repoll ODL Live (for example every 20 seconds), until your plan is ready.
If your model contains bad data which throws an error in the optimiser, it will still appear under completedstatic but no routes will be planned. You may however be able to get an error message by calling:
GET my-base-URL/modeltypes/completedstatic/myModelId/optimiserstateand then checking the errors field in the object that’s returned.
Unlike live models, completed models are never updated once they are available (e.g. ETAs for planned stops are never updated).
6.2.3 Utility endpoints for the static queue
The following other endpoints are also useful.
6.2.3.1 Get ids of all pending models in the queue
Do the following call:
GET my-base-URL/modeltypes/queuedstatic/ids6.2.3.2 Get status of all pending models in the queue
Do the following call:
GET my-base-URL/modeltypes/queuedstatic/statusThis returns an array with an object for each model in the queue. The object includes the id, the datetime the model was added to the database, a status field (which can be type RUNNING, QUEUED, or STOPPING) and statistics for each model that is currently running. These statistics include:
- plannedRoutes - the number of current routes in the solution.
- unassignedJobs - the number of jobs that have not loaded.
- cost - the total solution cost.
- iterations - completed iterations of the optimisation algorithm (generally you want several hundred to be completed for a reasonable solution).
- iterationsWithoutImprovement - the number of iterations that have passed since the solution was last improved.
- millis - the number of milliseconds that model has been optimising for.
- millisWithoutImprovement - the number of milliseconds that model has been optimising for since the solution was last improved.
6.2.3.3 Get status of specific model in the queue
Do the following call:
GET my-base-URL/modeltypes/queuedstatic/myModelId/statusThis returns the status object for the model. If the model has finished in the queue and is now available under completedstatic, the status field will be set to FINISHED. If you’re monitoring for a particular model to have finished, you can therefore keep polling this endpoint until the return object has status equal to FINISHED. Note that if an error occurred executing the model and optimisation could not be completed, it will still have status FINISHED (FINISHED does not indicate success or failure). In this case, check the optimiserstate endpoint for errors.
6.2.3.4 Deleting pending model from the queue
You can delete a model from the static queue using the following call.If the model is already optimising, it will stop optimising. No result will be available for the model under the completed endpoint.
DELETE my-base-URL/modeltypes/queuedstatic/myModelId6.2.3.5 Finish optimising a model early
You can request that the optimiser finishes running a model immediately (instead of waiting for the stopping criteria) by POSTing an object with JSON content {“finishNow” : true} to the following URL. Instead of deleting the model, the optimiser will finish running it as soon as possible and will still copy the plan over to the completed models.
POST my-base-URL/modeltypes/queuedstatic/myModelId/finishnow6.2.3.6 Get ids of all completed models
Do the following call:
GET my-base-URL/modeltypes/completedstatic/ids6.2.3.7 Get ids and completed times of all completed models
Do the following call:
GET my-base-URL/modeltypes/completedstatic/status6.2.3.8 Get the input model JSON for a completed model
Do the following:
GET my-base-URL/modeltypes/completedstatic/myModelId6.2.3.9 Delete a completed model
Do the following:
DELETE my-base-URL/modeltypes/completedstatic/myModelId6.2.4 Static models page
A static models page is available in the software developer’s dashboard (on webapp1 you must first set one or more threads to be available for running the static queue to see this page). This page lets you:
View the ids of all models in the static queue.
DELETE models in the static queue or set them to FINISH NOW.
View the cost and statistics for static queue models currently being optimised.
View a list of recently completed static queue model ids.
View maps for recently completed static queue models (but only showing straight lines between stops).
Download a route sheet for recently completed static queue models.
6.2.5 Automatic deletion of old completed static models
Completed static models do not use any system resource, apart from space in the database where they’re saved. The system will automatically delete old completed static models. By default it will keep the last 1000 completed models, so once you’ve processed 1000 static models, the system will delete the oldest model everytime you run a new one. In webapp2, the number of static models you can store is controlled by the following field in the application.json:
odl.optimiser.staticQueue.maxCompletedResults2KeepYou can set this higher if you need to retain more static models, but be aware that the system regularly parses a row per completed static model as part of its cleanup operations, so setting maxCompletedResults2Keep to millions may result in performance issues. This could also effect realtime models which are set to be deleted after a certain time, as this deletion takes place in the same cleanup operation.
6.2.6 Accessing road geometry for the static queue
By default, the geometry along the roads between stops is not available for static queue models - so it’s not available if you GET plan or view the map in the software developer’s dashboard. This is because geometry data is large and so by default is not stored in the database. You can enable geometry by setting:
model.configuration.reporting.staticQueueAndCommandLineRouteGeomAccuracyThe following JSON shows a model with this set to “STD” (standard) geometry:
{
"data": {
...
},
"configuration": {
"staticCPUBudget": {
...
},
"distances": {
...
},
"reporting": {
"staticQueueAndCommandLineRouteGeomAccuracy": "STD"
},
"timeOverride": {
...
}
},
"_id": "mymodel1"
}If you enable geometry in a static queue model, the geometry between roads will be available when you GET plan and when you view the map in the dashboard. staticQueueAndCommandLineRouteGeomAccuracy can have the following values.
STD. This simplifies the geometry to make it smaller when it’s saved to the database (the geometry is around 9x smaller than RAW). With STD if you zoom into the map enough, you will see that the geometry does not precisely follow the roads due to the simplification. This is ‘visual only’, all calculations inside ODL Live including ETAs use the correct road geometry, but we store a simplified version of it in the database to save on space. STD is the recommended option if you want geometry available for static queue models.
HIGH. This still simplifies the geometry, but it’s only about 3x smaller than RAW. You can zoom into the map significantly further than STD before you see distortions due to the simplification.
RAW. This does not simplify the geometry at all. You are not advised to use the RAW option.
ODL Live will save all geometry for a route within a single row in the database. The geometry is saved in a highly compressed format which is around 10x smaller than the GeoJSON. It is still possible if your routes have large amounts of geometry that you could encounter MySQL limits which prevent the geometry (and therefore the solution itself) being saved properly. This is unlikely to be a problem for STD accuracy but could be a problem for HIGH and RAW. You may therefore need to adjust the relevant limits on your backend database.
6.3 Command line API
6.3.1 Setting up the command line tool
To setup the command line, firstly ensure you have a 64-bit java 8 runtime installed on your computer. Java runtimes can be downloaded from AdoptOpenJDK. Next open a command line prompt and enter the following command:
java -versionThis command should start your 64-bit version of Java 8 and print out its version. If you have multiple versions of Java installed on your computer and 64-bit Java 8 is not the default version on your path, you can always run the correct java executable directly instead:
C:\Program Files\Path-to-java-install\bin\java.exei.e. replace the word ‘java’ with the full path to the correct java.exe in all the commands, to run the correct version of java.
Once you have the correct version of java running, copy the file odl.live.commandline.jar over to a suitable directory and open a command line prompt inside this directory. Then try the following commands:
java -Xmx4G -jar odl.live.commandline.jar -version
java -Xmx4G -jar odl.live.commandline.jar -helpThese firstly ensure Java can allocate up to 4 GB (using -Xmx) and then print the version and embedded help from the command line tool respectively. All commands to the command line tool will begin with:
java -Xmx4G -jar odl.live.commandline.jarIf you get an error similar to:
Invalid maximum heap size: -Xmx4G
The specified size exceeds the maximum representable size.you are probably running a 32 bit version of Java instead of a 64 bit version.
For most command line operations, you will also need to configure the licence key (see self-hosting installation guide for details).
6.3.2 Running models on command line
You can run models using ODL Live’s command line tool (available to self-hosted subscribers). You can run both next-day and realtime models on the command line. The following section explains how to run next-day day (i.e. non-realtime) models, this later section explains the extra steps required to run realtime models efficiently on the command line.
The command line could be used in event-driven serverless computing, if you configure an event to trigger the command line and to handle the JSON file input/output. You should only use streaming road network graphs files (this is standard graph format, with files ending in .odlsg) with the command line as non-streaming will require the whole graph be loaded.
Firstly see the section on setting up the command line for information on installing the command line utility.
The command to run a model is pretty simple, it takes the following arguments:
- Filename of the input model, in JSON format.
- Filename of the output plan.
On the following line we show how to use the -rm command to run a model, taking an input model with filename inputModel.json, and writing the generated plan object to the file outputPlan.json. The model will optimise for a maximum of 600000 (10 minutes) and will stop optimising when it reaches 50 iterations without any improvement:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -rmSetMaxMillis 600000 -rmSetMaxItWithoutImprove 50 -rm inputModel.json outputPlan.json-Xmx4G gives java 4GB of memory to run. The stopping criteria commands -rmSetMaxMillis and -rmSetMaxItWithoutImprove are detailed in this section.
If you are using a large road network file, assuming it’s a streaming file you will need to control how much gets loaded at once into the streaming graph cache. The -setRoadsMaxLoadedMB command controls this as follows:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -setRoadsMaxLoadedMB 300 -rmSetMaxMillis 600000 -rmSetMaxItWithoutImprove 50 -rm inputModel.json outputPlan.jsonFor large models (e.g. more than 500 jobs), you will likely want to set the optimiser to use multiple threads so it can make use of multiple CPUs (if you have them available on your server). The command -rmSetNbThreads controls this, as in the following example where we set 3 threads:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -rmSetNbThreads 3 -setRoadsMaxLoadedMB 300 -rmSetMaxMillis 1800000 -rmSetMaxItWithoutImprove 50 -rm inputModel.json outputPlan.json-setRoadsMaxLoadedMB, -rmSetNbThreads, -rmSetMaxMillis -rmSetMaxItWithoutImprove must all be called before -rm or they will have no effect. -setLicence should appear first of all.
When the optimiser runs, it will report to the console every few seconds:
13:50:11: it=10446 sol=[notLoads=0 routes=2 cost=201.19760516704935] runtimeMillis=10041/40000 itNoImprove=10437 millisNoImprove=9701/300000
13:50:11: ... solution cost breakdown: travel 1.1976051670493324, vehicle_fixed 200.0
13:50:16: it=20501 sol=[notLoads=0 routes=2 cost=201.19760516704935] runtimeMillis=15042/40000 itNoImprove=20492 millisNoImprove=14643/300000
13:50:16: ... solution cost breakdown: travel 1.1976051670493324, vehicle_fixed 200.0
13:50:21: it=31143 sol=[notLoads=0 routes=2 cost=201.19760516704935] runtimeMillis=20043/40000 itNoImprove=31134 millisNoImprove=19609/300000
13:50:21: ... solution cost breakdown: travel 1.1976051670493324, vehicle_fixed 200.0
13:50:26: it=41980 sol=[notLoads=0 routes=2 cost=201.19760516704935] runtimeMillis=25044/40000 itNoImprove=41971 millisNoImprove=24581/300000
13:50:26: ... solution cost breakdown: travel 1.1976051670493324, vehicle_fixed 200.0
13:50:31: it=52569 sol=[notLoads=0 routes=2 cost=201.19760516704935] runtimeMillis=30045/40000 itNoImprove=52560 millisNoImprove=29552/300000
1If you want to run for a fixed number of iterations and with no other limits on runtime, you can use the command -runModel which takes parameters (1) model filename, (2) number of iterations, (3) output plan filename. The following example runs a model for 100 iterations:
java -Xmx4G -jar odl.live.commandline.jar -runModel inputModel.json 100 outputPlan.json6.3.3 Optimiser stopping criteria
You should tell the command line how long it can optimise a model for. This can be done by either (a) using one or more additional -rmSetXXXX commands or (b) setting the model.configuration.staticCPUBudget object in your model JSON (exactly the same as you would do for static queue models).
The following commands set the stopping criteria, where each criteria (e.g. maxMillis) works exactly the same as the corresponding criteria in the staticCPUBudget object, as defined in the static queue section:
-rmSetMaxIt. Set the optimiser CPU budget variable maxIterations. Usage -rmSetMaxIt maxIterations
-rmSetMaxItWithoutImprove. Set the optimiser CPU budget variable maxIterationsWithoutImprovement. Usage -rmSetMaxItWithoutImprove maxIterationsWithoutImprovement
-rmSetMaxMillis. Set the optimiser CPU budget variable maxMillis. Usage -rmSetMaxMillis maxMillis
-rmSetMaxmillisWithoutImprove. Set the optimiser CPU budget variable maxMillisWithoutImprovement. Usage -rmSetMaxMillisWithoutImprove maxMillisWithoutImprovement
-rmSetMinIt. Set the optimiser CPU budget variable minIterations. Usage -rmSetMinIt minIterations
If you don’t set any stopping criteria, the default stopping criteria will let your model run for up to one hour.
6.3.4 Running realtime models on the command line (on-disk distances cache)
When running a realtime model on the command line you can either (a) continually run repeatedly in short optimisation bursts (e.g. run every 10 or 20 seconds) or (b) run for a longer amount of time but run it only when needed, i.e. when you want an updated plan. A realtime model should re-use the state from the previous time the model was run, so it can start up rapidly with minimal recalculations. To run realtime models on the command line you should do the following:
Use streaming road network graphs, so the only road network data that gets loaded is that required by new locations (i.e. locations added after the last optimisation burst).
Give the command line an initial solution to start optimising from. This should be the solution (i.e. JSON plan object) which was output the last time you ran the command line for the model.
Set the command line to use a distances state cache, stored on the local file system. The distances state stores the A to B travel matrix plus pre-processed data for each live location and gets updated when you run the optimisation burst. The distances state cache will only work with streaming graphs.
Set the stopping criteria to run a short optimisation burst (e.g. for 10 or 20 seconds) if you plan to continually re-run the model (e.g. do update input data, run model, update input data, run model, etc. repeatedly). If you plan to only run the model once-in-a-while and then reoptimise until you have a high-quality solution, you should run for longer.
The response time for running a realtime model on the command line is slower than running on the main endpoint because the main endpoint stores the model and distances state in-memory. The main benefit of using the command line for realtime is that server resources (memory and CPU) are only used when you actually run a model, so you could have a very large number of realtime models and only call optimisation on a model when you need an updated plan. From our tests, to update a small realtime model (e.g. 100 jobs) using the command line adds roughly 2 or 3 seconds ‘warm-up’ time per-burst compared to the main endpoint. Warm-up time includes initialising java, loading the distances state and any extra road network graph data that’s required. For larger models, or models with lots of new locations, warm-up time will be longer. If you’re continually re-running the model you should ensure your optimisation burst time is several times longer than the startup time, so you are using server resources efficiently.
6.3.4.1 Realtime models on command line walkthrough
We demonstrate running a realtime model on an example 250-job routing problem set on the Caribbean island of Aruba. This example demonstrates (a) using a streaming graph, (b) using the distances cache and (c) restarting from an existing solution. These are the three essential steps to follow when running a realtime model on the command line, as they minimise the amount of recalculation and loading done each time you the re-run optimisation.
The model JSON is available here:
supporting-data-for-docs\example-models\aruba-simple-vrp\model.jsonThe model also uses the road network directory stored here:
supporting-data-for-docs\road-networks\aruba-std-car-speeds.zipFirstly do the following:
Create a new empty directory.
Unzip aruba-std-car-speeds.zip into your directory, so your new directory should have a subdirectory aruba-std-car-speeds containing the road network data in streaming graph format.
Copy model.json into your new directory.
Copy odl.live.commandline.jar into your new directory.
Next open a command prompt inside your new directory and run the following command (remembering to enter your own licence key):
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -setRoadsMaxLoadedMB 1000 -dcSetDir "distcache" -rmSetMaxMillis 600000 -rmSetMaxItWithoutImprove 50 -rm "model.json" "plan.json"The command -dcSetDir tells ODL Live to use distcache as a distances cache directory. You already know the other commands - they will run the input model model.json for a maximum of 10 minutes, stopping when we reach 50 iterations without finding a better solution and then outputting the plan to plan.json.
When the command runs it will create both (a) the plan.json file and (b) the subdirectory distcache. Check the plan.json contains planned stops - if there is an issue with the path to the road network graph (e.g. you don’t have the subdirectory aruba-std-car-speeds containing the graph data), then no stops will be assigned.
Now you can run the command again but giving it the plan you just generated as an input parameter, using the -rmSetInitialPlan command, so the optimisation starts working from the solution you’ve just generated:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -setRoadsMaxLoadedMB 1000 -dcSetDir "distcache" -rmSetInitialPlan "plan.json" -rmSetMaxMillis 600000 -rmSetMaxItWithoutImprove 50 -rm model.json plan.jsonThe optimisation will start working from the previous solution saved in plan.json and may potentially improve it. In real-life if you were running a realtime scenario, each time you ran you would use a different version of model.json (e.g. with new jobs, different GPS coords for the vehicles etc).
The distances cache directory should contain one or more files ending in .odldc. Each time you run this model, providing you keep -dcSetDir set to the same directory, ODL Live will re-use the existing distances cache and update it as needed. The distances cache is designed to minimise the amount of data that’s written - typically it will only write one new small file each time the optimiser runs and the majority of files in the cache will not change. The cache also clears itself up automatically. If some of the location data is no longer needed for the optimisation, then once an existing file contains 50% or more data that is either no longer used or is duplicated in another file, it will be removed. Please note that models should never share the same distances cache directory, each model should have its own distances cache.
For this small problem, as the road network graph is very tiny - just the island of Aruba - the distances cache does not provide much of a speed-up. However if you run a large model (e.g. 1000+ jobs) in a more typical sized country, it can take a minute or so to calculate an initial distances matrix for the optimiser. If you don’t use the distances cache, you will have to do this calculation every time you run the command line. If you use the distances cache, instead of recalculating everything from scratch, the existing distances state will be reloaded and updated, which will be several times quicker than a complete recalculation.
If you placed the distances cache on a shared cloud file system (e.g. AWS’s elastic file system) which multiple servers (or serverless lambda methods) can access, then when you want to update a specific model, you can use any server. This makes horizontal scaling for realtime models simpler, as the model doesn’t need to stay on the same server for each burst.
The following commands are available to control the distances cache:
-dcSetDir. Set the distances cache directory. Distances cache will only be active if this is used.
-dcSetTargetChunkSizeBytes. The distances cache saves the data in multiple files and will attempt to keep each file’s size in bytes between dcSetTargetChunkSizeBytes and 2 × dcSetTargetChunkSizeBytes. Example usage -dcSetTargetChunkSizeBytes 10485760. On each run, the smallest file in the cache under dcSetTargetChunkSizeBytes gets replaced, so to minimise the total disk writing dcSetTargetChunkSizeBytes should be less than say 10 MB.
-dcSetCompress. Set files in the distances cache to be compressed or not. Compression is on by default, if you don’t compress your distances cache will take up roughly 2 to 3 times the amount of disk space. The time to startup and update the distances cache on each burst may sometimes be a bit faster with compression turned off, depending on read/write speed for your disk vs CPU speed for decompression/compression. Changing this setting does not effect files which are already written to the cache, only new files. Example usage: -dcSetCompress false.
6.4 Command line matrix generation
If you want to generate a large travel matrix, you are advised to do it using the command line and not the webservice matrix query. Compared to the webservice matrix query, command line matrix generation doesn’t have HTTP query timeouts or restrictions on the amount of memory which can be used (other than set in the java -Xmx setting). The command line matrix generation should be used with the streaming road network graphs format, which is the default format when you build a graph using the -buildRoadGraph command. You can tell if your graph data is in the streaming format as the graph files will have the extension .odlsg (for ODL Streaming Graph). As streaming graphs only load the parts of the graph they need, it will usually be significantly quicker to generate a graph on the command line using streaming graphs, compared to non-streaming graphs which must load the entire graph first. This makes the matrix generation with the command line suitable for serverless cloud computing environments (e.g. AWS lambda).
The matrix generation command (1) reads an input JSON file with your settings, data etc, (2) generates the matrix and (3) outputs the result to a text file. Two output formats are supported for the text file, CSV and JSON. The JSON format is exactly the same as the matrix object which gets returned in the JSON for the webservice matrix query. The CSV format is more suitable for storing large matrices, as some JSON parsing libraries might have trouble loading very large JSON files. The following command generates a CSV format matrix using the data in “input.json” and outputs the results to “output.csv”:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your_licence_key" -matrixgencsv "input.json" "output.csv"In the command we’re calling -setLicence before -matrixgencsv to tell ODL Live the licence key, but you could leave this command out and place the licence in a text file instead (see self-hosting guide for details). Setting -Xmx4G is also crucial, this is the total amount of memory in gigabytes the command line will have available to generate the matrix, if this is too small the matrix generation will be very slow and/or you will get an out-of-memory exception.
Here is an example input file:
{
"data": {
"froms": [
{"latitude": 51.81404414972939,"longitude": -0.15950407366801977,"id": "1" },
{"latitude": 51.169790177053045,"longitude": -1.0959129323133687,"id": "2" },
{"latitude": 51.927427690759764,"longitude": -0.44252588718435115,"id": "3"}
],
"tos": [
{"latitude": 51.81404414972939,"longitude": -0.15950407366801977,"id": "1" },
{"latitude": 51.169790177053045,"longitude": -1.0959129323133687,"id": "2" },
{"latitude": 51.927427690759764,"longitude": -0.44252588718435115,"id": "3"}
]
},
"distancesConfig": {
"graphDirectory": "C:\\myRoadNetworkData",
"roadNetworkTimeMultiplier": 1,
"type": "ROADS"
},
"maxLoadedMB4RoadNetworks": 1024,
"dontAddLatLongFields2CSVOutput": true
}The input file has the following fields:
data. The data object is exactly the same as the matrixRequest object in the webservice matrix query and supports several additional fields not shown here (e.g. timesUTC), which are detailed in webservice matrix query section.
distancesConfig. The distancesConfig is exactly the same as the model.configuration.distances object in your routing models. Different distance generations methods will have different JSON structure to that shown for distancesConfig above.
maxLoadedMB4RoadNetworks. This tells the command line how much memory in MB it can use to load the road network graph. For streaming graphs, if this is too small (e.g. less than a 1/5th or 1/10th of the graph size), performance will be impacted if your lat-long points are widely spread throughout the area covered by your road network graph.
dontAddLatLongFields2CSVOutput. If you set the field dontAddLatLongFields2CSVOutput to true, the output fields fromlatitude, fromlongitude, tolatitude and tolongitude will be kept out of the final CSV file. If you keep the lat-long fields in the output, you can use a CSV file output from the command line as an input matrix to your routing models.
Here’s an example output CSV file:
fromId,toId,Secs,Metres
"1","1",0,0
"1","2",4862.041,115172.648
"1","3",1984.063,39448.898
"1","4",8754.23,202284.438
"1","5",4088.368,88695.734
"1","6",8181.847,198069.688
"1","7",9445.865,224908.016
"1","8",9220.913,221909.469
"1","9",2940.013,70877.477
"1","10",5973.895,146561.078
....If you want to generate output JSON, use the command matrixgenjson instead of matrixgencsv.
6.5 Restarting from initial solution
In webapp2, you can store a model (with its plan and distances state) as inactive on the system and start/stop optimisation whenever you want using optimise requests. If instead you’re importing the model into the system (i.e. it’s not already on there), then all main methods to run a model also support starting optimisation from an initial solution. The initial solution should be saved within the model object, in the array model.data.initialVehiclePlans.
For the main endpoint, you should PUT the whole model at once using the PUT model endpoint (i.e. in a single HTTP PUT) when you first create the model, with model.data.initialVehiclePlans set inside the model JSON. Initial solution is not supported if you PUT the model over multiple HTTP PUTs - for example if you put an empty model first, then put vehicles, then jobs. If you PUT a model without an initial solution, and then later-on PUT a new version of the model (i.e. with the same model id) but with an initial solution, the initial solution will be ignored.
- You can therefore (1) PUT a model to the main endpoint, (2) leave it to optimise, (3) save the plan JSON outside of ODL Live, (4) DELETE the model, and then later-on (5) PUT the model again but with your saved solution.
For the command line you can either save the initial solution in model.data.initialVehiclePlans or use the -rmSetInitialPlan command (see section on running realtime models on the command line for usage).
For the static queue, include it in model.data.initialVehiclePlans when you do PUT model.
The following example model JSON shows the structure of the initialVehiclePlans array:
{
"data": {
"jobs": [],
"vehicles": [],
"initialVehiclePlans": [
{
"vehicleId": "v10",
"plannedStops": [
{"stopId": "s174"},
{"stopId": "s14"},
{"stopId": "s216"}
]
},
{
"vehicleId": "v13",
"plannedStops": [
{"stopId": "s105"},
{"stopId": "s199"},
{"stopId": "s41"}
]
}
]
},
"configuration": {},
"_id": "myModelId"
}You can copy the contents of the plan.vehiclePlans array from a plan generated by the optimiser into model.data.initialVehiclePlans, as both the generated plans and the initial plans use the same structure with the vehicleId, plannedStops and stopId fields. Extra fields in the generated plan (e.g. timeEstimates) will be safely ignored if you copy them into initialVehiclePlans.
6.6 Optimise requests
In webapp2 (only), you have more control over running a model using optimise requests. An optimise request is an object that’s associated with a model and tells ODL Live whether it should be optimised or not, and if it should be optimised as a static or realtime model. Using optimise requests you can keep a model saved on the system together with its plan and distances state, update or inspect the model whenever you need to, and then explicitly tell the system with an optimise request when you want the plan to be updated. When models are not set to optimise (i.e. they’re inactive) they use no system resources apart from database space.
6.6.1 Putting optimise requests
There are three types of optimise request:
realtime - runs as a realtime model which will keep on running forever, checking for updated input data, until the model is deleted or it’s changed to a different optimise request type.
static - runs the model as a static model which will stop running (and change to optimise request type inactive) once the stopping criteria is met. See separate static queue section for more information.
inactive - the model doesn’t run. An inactive model uses no system resources apart from database space. You can still modify the data in an inactive model (e.g. PUT job etc) but the plan will not be updated until you make the model active by sending a realtime or static optimise request.
When you PUT a model to the system in the normal way with the model stored in the JSON body, a realtime optimise request is automatically created. You can also control the optimise request type created with PUT model using the optreqtype parameter. For example:
PUT .../models/yourModelId?optreqtype=realtimeputs a model (stored in the JSON body) with a realtime optimise request and does exactly the same asPUT /models/yourModelId.PUT .../models/yourModelId?optreqtype=inactiveputs a model but it’s initially in the inactive state, so no burst will run or plan will be created until the user changes its optimise request type.PUT .../models/yourModelId?optreqtype=staticputs a model that’s set to run as a static model. It is assumed you’ve set the stopping criteria in model.configuration.staticCPUBudget otherwise webapp2 will use the default stopping criteria, which may run for longer than you want.
After you’ve PUT a model you can change its optimise request type
later-on as needed using the .../models/yourModelId/optreq
endpoint. You may change the optimise request type using either the
optreqtype parameter or by including a body with the optimise
request object. For example the following calls change the type using
the parameter and can have an empty json body:
PUT .../models/yourModelId/optreq?optreqtype=realtimePUT .../models/yourModelId/optreq?optreqtype=staticPUT .../models/yourModelId/optreq?optreqtype=inactive
PUT .../models/yourModelId/optreq?optreqtype=inactive is
actually just equivalent to calling
DELETE .../models/yourModelId/optreq as the inactive type
just means that the model has no optimise request, so deleting or
setting inactive do exactly the same thing.
You can also PUT by sending the body of the optimise request instead, which for the static queue also allows you to set the stopping criteria. For example:
PUT .../models/yourModelId/optreqwith JSON body{"requestType":"REALTIME"}is equivalent toPUT .../models/yourModelId/optreq?optreqtype=realtime.Set the model to static and set optimise criteria by calling
PUT .../models/yourModelId/optreqwith a JSON body like follows:{"staticCPUBudget": {"maxIterations": 1000,"maxMillis": 600000,"maxIterationsWithoutImprovement": 100},"requestType": "STATIC_MODEL"}Set a static model to finish now (so it terminates as soon as possible, whilst ensuring it saves its current solution) by calling
PUT .../models/yourModelId/optreqwith this JSON body:{"staticQueueFinishNow": true,"requestType": "STATIC_MODEL"}
Be aware that once a model has been run as static, it becomes subject to the automatic deletion of old static models, even if you run it as a realtime model afterwards or set it inactive explicitly.. See section on autodeleting old static models for more details on how to configure this.
6.6.2 Inspecting the current optimise request state for models
You can GET the current optimise request for a model by calling
GET .../models/yourModelId/optreq. You can also get the ids
of models filtering for their current optimise request state.
GET /models/ids?optreqtype=realtimeGET /models/ids?optreqtype=static`GET /models/ids?optreqtype=inactive
GET /models/ids?optreqtype=active
The finally GET checks for active request states, which
means it checks for models in either the realtime or static state.
6.6.3 Stopping a static model early - clean and dirty methods
If you don’t want to wait for a static model to complete, you can stop it either:
- the clean way, by sending a sending a finish now request to it, and
then wait for it to stop running. To see the if the static model has
stopped running, do
GET .../models/yourModelId/optreqto check the returned JSON has{ "requestType" : "INACTIVE" }.
- the clean way, by sending a sending a finish now request to it, and
then wait for it to stop running. To see the if the static model has
stopped running, do
or
- the dirty way, by deleting the optimise request or setting it inactive.
Using the dirty way, the newest in-memory plan for the model will not be saved (i.e. only the current plan already stored on database will remain). To prevent newest-plan-loss, ODL Live will not let you do a put a realtime optimise request to turn a static model into a realtime model unless you first send a finish now request to it, and then wait for it to terminate cleanly while saving. If you need to change the model to realtime immediately and you’re OK with not having the very latest plan you can of-course send the delete optimise request instead to a static model and then a put realtime optimise request (i.e. the dirty way).
6.7 Reporting and monitoring
The section details additional options for reporting data from ODL Live and monitoring its operations.
6.7.1 Monitoring optimisation iterations, bursts, last time input data loaded
You can get the current plan from the endpoint:
GET ../models/modelid/optimiserstate/planThe optimiser plan contains statistics on the number of optimiser iterations and bursts which have been run since the model was created. If you’re running a static (i.e. not realtime model), whose input data (jobs and vehicles) hasn’t changed since you first PUT the model, you can use the total number of iteration to decide when your model has run for long enough. For example, you might decide that for your typical model size, you get a reasonable solution after running 250 iterations. Using the iterations count is useful because if you’re running multiple models in-parallel, each model will get less CPU time, and so you can’t simply run the models for a fixed amount of wallclock time. In contrast, the iterations count tells you that a set amount of optimisation has been performed on the model, irrespective of the number of models running in-parallel with it.
In the plan object, you get the iterations and burst counts from the following fields:
{
"vehiclePlans" : [ ],
"statistics" : {
"nbOptIterations" : 132,
"nbOptBursts" : 5,
}
}The other fields in the statistics object are considered to be internal to the engine and should not be used by client code.
If instead you get the whole optimiser state from this endpoint:
GET ../models/modelid/optimiserstate/planyou will get a JSON object which looks like the following:
{
"masterPlan" : {
....
},
"performance" : {
....
},
"timeUTCLastBurstStartedLoadingData" : "2024-06-26T07:09:07.188",
"sprintPlan" : {
...
},
"alternatePlans" : [ ... ]
}This has a field timeUTCLastBurstStartedLoadingData which contains the time in UTC that the input data (model etc.) was loaded from the database before starting the last optimisation burst. So if you make a change to the data (e.g. add a new job, change GPS location) and want to know if that change has been incorporated in the latest plan, check if timeUTCLastBurstStartedLoadingData is after the PUT data request you made. For larger data changes, the optimiser may require several bursts to properly re-optimise the plan around the data change.
6.7.2 Monitoring data changes for a model
By default, ODL Live maintains a short history of changes to the numbers and ids of jobs, stops and vehicles. This is available via the optimiser state, if you do the following GET:
GET .../models/modelid/optimiserstateThe history is available in optimiserstate.modelHistoryTracking which has the following properties:
logRecentModelDataIdChangesFromHttpWrites - a log of changes to ids which is updated on each HTTP write to the model.
logRecentModelDataIdChangesFoundInBurst - a log of changes to ids which is updated on each optimisation burst, and compares the model loaded in the burst with the ids from the previous burst.
Please note not all of these are available in the legacy version of ODL Live which runs in Apache Tomcat (the ROOT.war version). Here’s an example JSON showing some of these change logs:
{
"masterPlan": {},
"modelHistoryTracking": {
"logRecentModelDataIdChangesFoundInBurst": [
{
"timeUTC": "2025-03-19T00:31:14.51",
"changes": [
{
"code": "NEW_VEH", "trimmedExampleIds": [ "v0", "v1"],
"count": 2
},
{
"code": "NEW_JOB",
"trimmedExampleIds": [ "j0", "j1", "j2"],
"count": 3
}
],
"totalVehRecs": 2,
"totalJobs": 3,
"burstNb": 0,
"totalUndispatchedOrPartiallyDispatchedJobs": 3
},
{
"timeUTC": "2025-03-19T00:31:18.487",
"changes": [
{
"code": "MISSING_OR_DISPATCH_JOB",
"trimmedExampleIds": ["j0"],
"count": 1
}
],
"totalVehRecs": 2,
"totalJobs": 2,
"burstNb": 2,
"totalUndispatchedOrPartiallyDispatchedJobs": 2
}
],
"logRecentModelDataIdChangesFromHttpWrites": [
{
"timeUTC": "2025-03-19T00:31:12.487",
"changes": [
{
"code": "NEW_VEH",
"trimmedExampleIds": ["v0", "v1" ],
"count": 2
},
{
"code": "NEW_JOB",
"trimmedExampleIds": ["j0", "j1", "j2"],
"count": 3
}
],
"totalVehRecs": 2,
"totalJobs": 3,
"endpointCode": "HTTP_PUT_MODEL_JSON"
}
]
}
}If the optimiser state is not available yet (because a burst has not yet happened for the model), by default you will not get any state back, and no data logs. If you want to see the data logs before a burst has completed, you can use the following parameter:
GET .../models/modelid/optimiserstate?alwaysFetchDataLogs=trueBy default only 100 records are stored for each data changes log, for performance reasons. You can increase this by setting parameters in model.configuration.reporting. Here we have an example JSON showing the reporting object inside the model object with these overrides set:
{
"data" : {
},
"configuration" : {
"distances" : {},
"reporting" : {
"nbRecentIdChangesInModel2TrackOnBursts" : 1000,
"nbRecentIdChangesInModel2TrackFromHTTPWrites" : 1000,
"overrideMaxNbHistoricImprovements2Keep" : 1000
}
}
}We set the the model to log 1000 entries for (a) id changes found in the bursts, (b) id changes from all HTTP writes and (c) the history of improvements to the solution quality (costs, number of routes etc). We do not recommend setting these numbers to more than 1000 for performance reasons.
6.7.3 Accessing extra information from GET plan
You get the plan JSON object from:
GET /models/{modelId}/optimiserstate/planAs we want to keep this object relatively small, there are some pieces of data which we keep out of the plan by default, as they’re not always needed. You can add these to the plan using parameters. The following sections detail this.
6.7.3.1 Route geometry in the plan object
You can get the route geometry between stops (i.e. route along roads between two points) when you GET the plan using the geometry URL parameter, e.g.
GET /models/{modelId}/optimiserstate/plan?geometry=STDThe geometry=STD tells the request to include the geometry in the JSON and use standard geometry accuracy (all possible values are NO_GEOMETRY, STD, HIGH, RAW). The geometry appears as a GeoJSON in each of the plannedStop’s geomToNextStop fields and in the geomToFirstStop in the vehicle plan.
The route geometry is also available through the upcoming stops view which presents a simpler view compared to the plan object, if your focus is on the pending stops regardless of whether they have been dispatched or not.
6.7.3.1.1 Accessing route geometry for dispatched incomplete / future stops
Stops are either dispatched or undispatched. Undispatched stops are constantly being planned by the optimiser and we therefore use the terms ‘undispatched’ and ‘planned’ interchangeably, i.e. ‘planned’ and ‘undispatched’ have the same meaning and when we say ‘planned’ we actually mean ‘planned but not yet dispatched’. Dispatched stops are either (a) complete or (b) incomplete. Together the dispatched incomplete stops and the undispatched/planned stops comprise all the stops the vehicle has coming up.
The route geometry for dispatched incomplete plus the undispatched stops is therefore all the route geometry coming up (i.e. geometry of all roads the vehicle will drive down from the current time onwards). To make ODL Live generate the route geometry for the dispatched-incomplete stops as well as planned (which it generates by default), set the following fields in model.configuration.reporting:
{
"data" : {
"jobs" : [ ],
"vehicles" : [ ]
},
"configuration" : {
"reporting" : {
"outputEmptyVehiclePlans" : true,
"createRouteGeoms4DispatchedIncomplete" : true
}
}
}If you set this in the configuration, then when you GET the plan, the list of dispatchedIncompleteStops will contain geometry in their geomToNextStop fields. A field dispatchedIncompleteGeomToFirstStop will also appear, as per this plan JSON:
{
"vehicleId": "vehicle1",
"dispatchedIncompleteStops": [
{
"stopId": "3",
"timeEstimates": {
"arrival": "2001-01-01T10:43:50.887939453",
"start": "2001-01-01T10:43:50.887939453",
"complete": "2001-01-01T13:01"
},
"geomToNextStop": {
"type": "LineString",
"coordinates": [
[-0.40889104826456096,51.54786868382734],
...
[-0.4370853402559163, 51.54984056688489]
]
}
}
],
"dispatchedIncompleteGeomToFirstStop": {
"type": "LineString",
"coordinates": [
[0.10042272242691638, 51.55674983365317],
...
[0.09916722996161648,51.54820032152981]
]
},
"geomToFirstStop": {
"type": "LineString",
"coordinates": [
[-0.3601321906460218,51.568046800852166],
...
[-0.41290673791728905, 51.57503660963395]
]
},
"plannedStops": [
...
]
}The logic works as follows:
If you have no dispatched-incomplete stops, then all dispatched stops have been completed (or there are no dispatched stops) and the vehicle’s next stop is assumed to be the first stop in
plan.plannedStops. The fieldplan.geomToFirstStopis the geometry to the first planned/undispatched stop.geomToFirstStopwill therefore contain the route geometry from the vehicle’s current position (which could be a GPS position or its last known stop, whichever is latest) to the next planned/undispatched stop.If you have dispatched-incomplete stops then providing createRouteGeoms4DispatchedIncomplete is true, the field
plan.dispatchedIncompleteGeomToFirstStopwill contain the route geometry from the vehicle’s current location (which could be a GPS location) to its next dispatched-incomplete stop (i.e. the next stop it will physically do). If you have (for example), two dispatched-incomplete stops and one planned stop after them, then:plan.dispatchedIncompleteGeomToFirstStophas the route geometry from the current location to the first dispatched incomplete stop.In
plan.dispatchedIncompleteStops[0], the fieldgeomToNextStophas the route geometry from the first dispatched incomplete stop to the second.In
plan.dispatchedIncompleteStops[1], the fieldgeomToNextStophas the route geometry from the second dispatched incomplete stop to the first undispatched (i.e. planned) stop.In
plan.plannedStops[0]the fieldgeomToNextStophas the route geometry from the first undispatched/planned stop to the vehicle’s end depot location (if the depot is set).
In other words:
If there are no dispatched-incomplete jobs (i.e. the array
plan.dispatchedIncompleteStops is empty), all the upcoming
route geometry is in plan.geomToFirstStop and
plan.plannedStops[].geomToNextStop.
If you have dispatched-incomplete stops (i.e. the array
plan.dispatchedIncompleteStops is not empty), then
plan.dispatchedIncompleteGeomToFirstStopand
plan.dispatchedIncompleteStops[].geomToNextStopcontain the route geometry to/from dispatched-incomplete stops and
plan.plannedStops[].geomToNextStopcontains the route geometry from all undispatched stops.
6.7.3.1.2 Accessing route geometry for all dispatched stops
By default the system will not generate route geometry for dispatched stops (both complete and incomplete), as it doesn’t need this for its default map view. The following configuration settings in the model will force the system to generate and cache the route geometry along roads between dispatched stops as well:
{
"data" : {
"jobs" : [ ],
"vehicles" : [ ]
},
"configuration" : {
"reporting" : {
"outputEmptyVehiclePlans" : true,
"createRouteGeoms4OldJourneys" : true
}
}
}To access the geometry including dispatched, when you GET the optimiser plan, use the following two parameters:
GET /models/{modelId}/optimiserstate/plan?include-dispatched=true&geometry=STDThe include-dispatched parameters adds all the dispatched stops (whether they are complete or incomplete) to the list of plannedStops in the vehicle plan.
6.7.3.2 Enabling detailed statistics
Some per-stop statistics are hidden by default when you get the plan using:
GET /models/{modelId}/optimiserstate/planThis is to reduce the size of the JSON returned. If you want these stats available, you should set the field model.configuration.reporting.detailedStats4PlannedStops to true, as in the following example model configuration:
{
"distances" : {
....
},
"optimiser" : {
.....
},
"reporting" : {
"detailedStats4PlannedStops" : true
},
"timeOverride" : {
......
}
}The fields which you’ll see when you enable this are in vehiclePlan.plannedStop[].timeEstimates (i.e. in each planned stop in the plan) and in vehiclePlan.planEndPoint. These fields are:
arrivalTimeB4ParkExclDistConfPark. Arrival time at the stop before parking time is applied, excluding parking time set in the distances configuration (i.e. only parking time set on the stop or the vehicle object).
cumulativeTravelKm. The cumulative travel along the route until the stop.
latenessHours. How late the stop was. If custom lateness penalties are used, the ‘late region’ is defined as the value of arrival time when a non-zero penalty is applied. Together with the cost breakdown in enrouteOptCosts (see below), this allows you to see the lateness and associated costs for each stop.
onboardTimeCalculationStats - an object containing statistics related to the onboard time calculation.
travelHoursBefore. The travel hours from the preceeding stop to the stop. For the first planned stop, this is the travel from the time and position where the optimiser can start planning the vehicle (i.e. where the vehicle is next free), to the planned stop. Depending on the vehicle state this ‘next free’ position could be the depot, the last dispatched-incomplete stop or the last vehicle GPS point.
travelKmBefore. The travel km from the preceeding stop to the stop.
A data structure called enrouteOptCosts is also added to each planned stop and the plan end point when you enable detailed statistics. This stores the value of costs which occur when the vehicle serves an individual stop (i.e. they are ‘enroute’ costs), e.g. travel, lateness etc.
To make the travelHoursBefore and travelKmBefore fields available for dispatched-incomplete stops as well, also set detailedStats4DispatchedIncompleteStops to true like so:
"reporting" : {
"detailedStats4PlannedStops" : true,
"detailedStats4DispatchedIncompleteStops" : true
},The following summary objects are also added to each route and to the whole solution:
singleRouteJobsOverDirectBasedOnboardLimit - count of jobs which are over the direct-based onboard travel time limit.
lateStopsByType - total number of late stops for each stop type.
lateSecondsByStopType - total late seconds for each stop type.
6.7.3.3 Including properties in the plan
You can store your own fields in the properties object, within stop, vehicle or model objects. Properties lets you store key-value pairs of strings. If you want to include this information in the plan object, use the additional parameters include-stop-props, include-vehicle-props or include-model-props, for example:
GET /models/{modelId}/optimiserstate/plan?include-stop-props=trueYour stop object’s properties will appear in the stopProperties field of the planned stops. Vehicle level properties will appear in the vehicleProperties field of the vehicle plan and should be defined in the vehicle object (not the vehicle.definition object). Model level properties will appear in the modelProperties field on the plan and should be defined in the model object, not the model.data object.
There is also a CommandLine command which can be used to trigger this same logic for stops (only) if you set it to true (it is false by default). It should be called together but before commands which are reading and solving ODL models. It doesn’t have any input parameters, it simply turns the logic on and should be used blank (no parameters):
-rmSetIncludeStopPropsInJSONPlanUser can test this command using example model “1-job-model-with-properties.json”, found in supporting-data-for-docs\example-models\custom-fields-in-excel-report.
Example command would take Stop properties set inside “1-job-model-with-properties.json” and put them inside final “outputPlan.json” :
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -rmSetIncludeStopPropsInJSONPlan -rm 1-job-model-with-properties.json outputPlan.jsonSnippet of final Plan JSON below contains these custom Stop properties now:
"earliestDispatch" : "2021-12-31T23:49:59.999979648",
"stopProperties" : {
"hello" : "apple",
"there" : "banana",
"world" : "peach"
}
} ],
"planStartPoint" : {6.7.3.4 Changing the output timezone
All output times are in UTC, as ODL Live uses UTC internally. You can however change the timezone ODL Live displays when (a) outputting from the GET plan endpoint, (b) exporting the route sheet or Excel, (c) shown in the software developer’s dashboard and (d) using the command line. To change the output timezone, set model.configuration.reporting.outputTimezoneId to the appropriate timezone id (see list of timezone ids). In the following JSON this model outputs ETAs etc in the America/Aruba timezone:
{
"data": {},
"configuration": {
"distances": {},
"reporting": {
"outputBurstTiming": true,
"outputTimezoneId": "America/Aruba"
},
"timeOverride": {
"override": "2022-05-10T04:00",
"overrideType": "SCHEDULER"
}
},
"_id": "myModelId"
}6.7.4 Upcoming stops and geometry simple view
The upcoming view endpoint provides a JSON with a simplified view of the plan, focused on the upcoming stops (both dispatched but incomplete and not yet dispatched), together with their geometry. Route geometry will only be available for dispatched incomplete stops if the following field is set in model.configuration.reporting:
{
"data" : {
"jobs" : [ ],
"vehicles" : [ ]
},
"configuration" : {
"reporting" : {
"createRouteGeoms4DispatchedIncomplete" : true
}
}
}The upcoming view is available from the endpoint:
GET ../models/{modelId}/optimiserstate/upcomingview?geometry=STDThe parameter geometry can be type NO_GEOMETRY, STD, HIGH or RAW. If the parameter is not included in the URL, it is assumed to be of type NO_GEOMETRY. If road networks are used, the geometry will the geometry along the roads between stops, otherwise it will be a straight line.
The following JSON shows the structure of the upcoming view:
{
"vehicles" : [
{
"upcomingStops" : [
{
"stop" : {
... stop object from the model, including stop id and coordinate
},
"timeEstimates" : {
... arrival, start and completion time estimates
},
"geomToMe" : {
... GeoJSON from last stop/last vehicle position to the stop
},
"type" : "DISPATCHED_INCOMPLETE"
},
{
"stop" : {...},
"timeEstimates" : {...},
"geomToMe" : {...},
"type" : "DISPATCHED_INCOMPLETE"
},
{
"stop" : {...},
"timeEstimates" : {...},
"geomToMe" : {...},
"earliestDispatch" : "2001-01-01T02:35:50",
"type" : "PLANNED"
},
{
"stop" : {...},
"timeEstimates" : {...},
"geomToMe" : {...},
"earliestDispatch" : "2001-01-01T02:50:29",
"type" : "PLANNED"
},
{
"stop" : {...},
"timeEstimates" : {...},
"geomToMe" : {...},
"type" : "VEHICLE_END"
}
],
"lastGPSTrace" : {
"time" : "2001-01-01T01:02",
"coordinate" : { ... },
"type" : "GPS_DEVICE",
"_id" : "9NgIl66PRgu9kR4jKrZaFw=="
},
"vehicleId" : "Vehicle1"
}
]
}The view contains a list called vehicles which has an object for each vehicle with upcoming stops - either dispatched-but-incomplete stops or planned stops. Each object for a single vehicle has the following fields:
upcomingStops - list of upcoming stop objects. These are ordered in the expected order they will be completed, so dispatched-but-incomplete appear first, then planned but not yet dispatched, and then a stop object for the vehicle end location if (and only if) the vehicle has an end location set.
lastGPSTrace - last GPS trace object for the vehicle.
Each upcoming stop object within a vehicle object has the following fields:
stop - the stop object from the model, which contains stop id, coordinate and the other fields.
timeEstimates - arrival, start and completion time estimates for the stop.
geomToMe - GeoJSON from the position prior to the stop, to the stop itself. The prior position could be vehicle start, last GPS trace or previous stop depending on the route state.
earliestDispatch - the earliest time the stop should be dispatched, if it’s a planned but not yet dispatched stop.
type - the type could be DISPATCHED_INCOMPLETE, PLANNED or VEHICLE_END.
If the vehicle has breaks defined in its preloadedStops, these will also appear in the list of upcoming stops, except their geomToMe field will be null, and the next non-break stop’s geomToMe field will have the whole geometry from the previous non-break location to itself.
You can get the upcoming view for just one vehicle by adding the vehicle’s id to the end of the path:
GET ../models/{modelId}/optimiserstate/upcomingview/{vehicleId}?geometry=STD6.8 Webhooks - callback when routes change
You can add webhooks to the model configuration object to call back to your system with an HTTP POST, when the planned routes have changed. Webhooks are designed to facilitate syncing of planned routes stored within your own system to the ‘master’ planned routes held within ODL Live. The webhook is fired when the stops assigned to one or more vehicles change - i.e. stops are re-ordered or moved to other vehicle(s). Webhooks do not fire when only the estimated arrival times change.
The model configuration object stores a list called webHooks. A WebHook object has a type which should be equal to PLANNED_ROUTE_CHANGED and a URL that you set. So, within the model configuration object you would define the list of webhooks like so:
"webHooks" : [ {
"url" : "http://www.opendoorlogistics.com/testing-webhooks-v2.html",
"type" : "PLANNED_ROUTE_CHANGED"
} ],The webhooks POST an object to the URL containing the planned stop ids for all routes which have changed. You should therefore have a POST end-point setup on this URL. Here is an example POST body for just one route changed (note if multiple routes have changed you will have multiple entries in the array modifiedPlannedRoutes).
{
"modelId" : "TestModel1",
"modifiedPlannedRoutes" : [ {
"vehicleId" : "TestVeh1",
"plannedStopIds" : [ "74", "44", "4", "38", "65" ]
} ]
}The message is deliberately compact - only the ids of the stops in
the route are sent and not the estimated times (as the times will change
more often than the stop ids). It is anticipated that the message will
be sent often after a substantial change to the data (causing planned
routes to change) but will quieten down when no changes are sent to the
input model for a while.
Dispatching a stop will also cause the message to be sent - as the first
stop is removed from the planned route and added to the end of the
dispatches.
If jobs have become unloaded (i.e. unassigned), their ids will also be included in the webhook, in the list newUnplannedJobIds:
{
"modelId" : "TestModel1",
"modifiedPlannedRoutes" : [ {
"vehicleId" : "TestVeh1",
"plannedStopIds" : [ "74", "44", "4", "38", "65" ]
} ],
"newUnplannedJobIds" : [
"job2","job7"
]
}In the current version of ODL Live, webhooks are not persisted to the database layer before being sent (they are not persisted primarily to reduce data transfer and avoid slowing down the optimiser). As a result, if the optimiser server was to failover after a route changed but before the webhook was sent, the webhook could be lost and never sent. You should therefore use webhooks as part of a combination strategy to keep your systems updated with the planned routes, e.g.
Update planned routes on your system whenever webhook received.
Poll for the planned routes every X minutes (e.g. every 5 minutes), refreshing all planned routes in your system.
6.9 Input and output using Excel instead of JSON
For non-realtime models, ODL Live supports input/output with Excel instead of JSON.
6.9.1 Excel input using templates
6.9.1.1 Templates overview
You can input a model into ODL Live using an Excel, and get the output plan in Excel as well. If you input a model using Excel, you must use templates. Templates make it simpler to create ODL Live models, and let you use ODL Live without having to use JSON. For non-realtime vehicle routing problems, an end-user can therefore use ODL Live without having to write a computer program to create or parse JSON, i.e. templates and input/output using Excel provide a ‘workflow’ to use ODL Live without programming.
A template file tells ODL Live how to translate a set of the user’s fields into an normal ODL Live JSON object (e.g. ODL Live job or vehicle object). You can define your model in an Excel format and ODL Live will use templates to turn it into an ODL Live model.
The zip file supporting-data-for-docs\walkthroughs\templates.zip contains examples of templates and template input data. Open the Excel file aruba-delivery-model.xlsx inside the zip and look at the jobs tab. We have jobs data in the following format:
| id | latitude | longitude | quantity | stopSecs |
|---|---|---|---|---|
| Customer1 | 12.55301 | -70.04223 | 1 | 120 |
| Customer2 | 12.50952 | -69.97612 | 2 | 120 |
| Customer3 | 12.53560 | -70.04915 | 3 | 60 |
| Customer4 | 12.54755 | -70.04162 | 5 | 120 |
| Customer5 | 12.52885 | -69.98533 | 1 | 120 |
The file aruba-delivery-model.odlt is an ODL Live template file. At its top, it contains the following template:
# job
{
"quantities": [
{{quantity}}
],
"stops": [
{
"type": "DELIVER",
"durationMillis": {{secs2millis stopSeconds}},
"coordinate": {
"latitude": {{latitude}},
"longitude": {{longitude}}
},
"_id": "{{id}}"
}
],
"_id": "{{id}}"
}The title ‘# job’ tells ODL Live this template should be used for a job. The title format is ‘# template-id’ where ‘job’ is the special template id to apply to jobs. Everything below the title is the template.
The template is using the handlebars.java templating language, which follows the conventions used in handlebars.js. If you have been supplied templates for your job and vehicle objects, then you don’t need to generate JSON and you can use ODL Live for non-realtime by just passing it Excel files. The template contains fields from the input Excel which are surrounded by double curly braces (e.g. {{quantity}}). It also uses one built-in helper function secs2millis which converts the stopSeconds defined in the Excel jobs table into the durationMillis field used by ODL Live.
Instead of inserting the template fields into the JSON (e.g. {{quantity}}), you can also copy and paste a normal JSON object from a model directly into the template and define a separate json2Template section which tells ODL Live how to turn the normal JSON object into a template (see next section for details). Using json2Template means you can still use normal JSON editors to edit your templates.
aruba-delivery-model.odlt also contains templates for the vehicle object and the model configuration object. Templates can be held in a separate .odlt file or they can be copy-pasted into the first column (column A) of a sheet called templates in your Excel. If you look at the templates sheet in aruba-delivery-model.xlsx, you will see it has the templates from aruba-delivery-model.odlt pasted into it.
If you create a new model using the ODL Live software developer’s dashboard, you must have your template data in the templates sheet as the dashboard doesn’t support creating a model using an .odlt (but the PUT model endpoints and command line do support this).
The configuration sheet in the Excel gets translated using the configuration template into the ODL Live model configuration object (which appears in model.configuration in the model JSON). The configuration sheet in aruba-delivery-model.odlt contains the following data:
| key | value |
|---|---|
| sourceTimezone4TimeWindows | America/Aruba |
| roadNetworkGraphDirectory | C:\Users\ …… \aruba-std-car-speeds |
| currentTime | 2022-05-10T00:00:00 |
| roadNetworkTravelTimeMultiplier | 1 |
If you have the field sourceTimezone4TimeWindows in the configuration sheet, ODL Live will uses this timezone id to translate the input times (e.g. for time windows etc) from local time to the UTC time zone ODL Live uses internally. You can therefore use templates to specify use your input data in your own local timezone, instead of UTC. See this wikipedia page for list of timezone ids. You can also setup a model to export ETAs in a different timezone.
To use this input Excel on your own computer, you must unzip the following road network graph to a directory on your file system:
supporting-data-for-docs\road-networks\aruba-std-car-speeds.zipYou should then change the Excel so the roadNetworkGraphDirectory value in the key-value configuration sheet points to this unzipped location on your file system. For both the main endpoint and the static queue, the software developer’s dashboard has a button ‘Upload new model in Excel-with-template format’ which lets you upload this Excel and run it.
You can use templates when you PUT model to either the main endpoint or the static queue. You should set the Content-Type HTTP header of your request to ‘multipart/form-data’ and the body of your request must (a) contain the Excel and (b) can also contain any number of .odlt files defining the templates. You can use the free Postman app to test creating HTTP requests with an Excel which you send to ODL Live. Templates are not currently supported for the other ODL Live endpoints (e.g. not supported for PUT job), only for PUT model.
When you’re calling PUT model, you can therefore send any of the following data:
Excel with Content-Type header Multipart/form-data, with the HTTP body containing an Excel and optional .odlt files to be converted into a normal ODL Live model JSON.
User JSON. See next section for details. A JSON model with a templates list, where the structure of jobs, replenishJobs, vehicles and configuration are the user’s own fields instead of the normal ODL Live fields. The templates then convert the user’s fields to a normal ODL Live model JSON.
Normal model. A normal ODL Live model JSON.
6.9.1.2 Using templates with a ‘user format JSON’ instead of Excel
You can also PUT model as a JSON containing a templates object, and ODL Live will use these templates to translate your JSON data into ODL Live’s normal JSON data. The JSON data can be in your own format (i.e. ‘user format’) although the top-level fields must be (1) configuration, (2) templates and (3) data, where data must contain arrays called jobs, vehicles etc. The fields within configuration and the fields defining the objects in jobs and vehicles can be your own fields with your own fieldnames, which are referenced by the templates. The file aruba-delivery-model-pre-template.json shows a ‘pre-template’ / user JSON which you can send to the PUT model endpoint. Its structure is as follows:
{
"configuration": {
"sourceTimezone4TimeWindows": "America/Aruba",
"roadNetworkGraphDirectory": "C:\\Users\\info\\Dropbox\\Business\\SharedDirectories\\SharedDevelopment\\ODLLive\\UnitTestData\\aruba-std-car-speeds",
"currentTime": "2022-05-10T00:00:00",
"roadNetworkTravelTimeMultiplier": "1"
},
"templates": [
{
"id": "job", "template": "job template contents...."
},
{
"id": "vehicle", "template": "vehicle template contents...."
},
{
"id": "configuration", "template": "config template contents...."
}
],
"data": {
"vehicles": [
{
"id": "BigVan1",
"latitude": "12.5530142955238","longitude": "-70.0422316047763",
"open": "2022-05-10T08:00:00","close": "2022-05-10T16:00:00",
"capacity": "40"
}
],
"jobs": [
{
"id": "Customer1",
"latitude": "12.5530142955238","longitude": "-70.0422316047763",
"quantity": "1",
"stopSeconds": "120"
},
{
"id": "Customer2",
"latitude": "12.5095283911294","longitude": "-69.9761248551966",
"quantity": "2",
"stopSeconds": "120"
}
]
}
}Compared to the Excel, the contents of the configuration, jobs, vehicles and templates sheets have been moved to model.configuration, model.data.jobs, model.data.vehicles and model.templates respectively (i.e. this JSON is another representation of the Excel data with the data moved around). The fields inside configuration, jobs and vehicles match the fields in the Excel. These fields are used within the templates, different templates could therefore have different fields defined with different names. The field sourceTimezone4TimeWindows is still present in the configuration object, when the templates are applied the datetimes within the model will therefore be transformed into the UTC which ODL Live uses internally.
6.9.1.3 Using templates with the command line
You can also run models using templates on the command line. This section explains how to run models on the command line. Your input model can be an Excel, user JSON or normal model providing you also supply the templates required to convert the Excel or user JSON.
The following command uses the -tmplLoad to load two different template files (templates1.odlt and templates2.odlt) and then runs the model defined in the Excel inputModel.xlsx (using the templates to convert it to a normal ODL Live model).
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -tmplLoad "templates1.odlt" -tmplLoad "templates2.odlt" -rmSetMaxMillis 600000 -rmSetMaxItWithoutImprove 50 -rm inputModel.xlsx outputPlan.jsonThe command -tmplLoad must be called before the run model -rm command. The -rm command uses the file extension to decide whether the input is an Excel or JSON (anything not ending in .xlsx or .xlsx is assumed to be JSON).
You can also use the command line to generate the output JSON model (i.e. after the template has been applied) and then save it to disk, using the -tmplApply command:
java -jar odl.live.commandline.jar -setLicence "your-licence-key" -tmplLoad "mytemplate.odlt" -tmplApply "inputModel.xlsx" "outputModel.json"6.9.1.4 Utility methods for working with / debugging templates
The webapp and command line both contain helper methods for working with templates. These methods take an input model in either Excel or user JSON format together with the templates, and return the normal ODL Live model. You can use these methods to test that your templates are working correctly.
The webapp supports the following endpoints, which support the same content type and body data as PUT model and require that you set the Content-Type header to Multipart/form-data if you’re sending an Excel:
POST /helpers/process-model-template?level=pre-template. This takes the Excel+ templates and converts it to a ‘user JSON’ (i.e. maps the Excel to a user JSON). If you pass it a ‘user json’, it will just return the JSON you posted.
POST /helpers/process-model-template?level=post-template. This takes an Excel+templates or a user JSON, applies the templates and returns the result.
POST /helpers/process-model-template?level=final. This takes an Excel+templates or a user JSON, applies the templates and then matches it to a normal ODL Live JSON model. In this final matching step, fields which don’t exist in a normal ODL Live JSON will be removed and ODL Live may populate some missing fields with default values. The returned JSON is the final JSON which ODL Live will use internally.
To use these POST methods with Postman you should:
- Create a new tab for a new request.
- Set the URL, e.g. http://localhost:8080/helpers/process-model-template?level=final
- Set the method to POST.
- In the Body tab, do the following (also see screenshot image):
- Select form-data.
- Under key, select any string for the key and change the type to file.
- Under value, click the Select files button and select your file.
- Repeat multiple times if you’re using separate .xlsx and .odlt files.
- Under the Authorization tab, enter your normal Authorization details.
- Check that under the Headers tab, Postman has automatically set the Content-Type header to multipart/form-data; boundary=<calculated when request is sent>. Warning - if you start with an existing request and change it to form-data, Postman does not automatically add the boundary information and your request will fail with an internal server error.
- Finally press POST.
The following screenshot shows how the Body tab should look:
You can also call the level=final function via the command line using the command -tmplApply:
java -jar odl.live.commandline.jar -setLicence "your-licence-key" -tmplLoad "mytemplate.odlt" -tmplApply "inputModel.xlsx" "outputModel.json"6.9.1.5 Advanced templating language features
The handlebars templating language lets you embed one template in another using the {{> templatename}} notation, and also lets you override values in a template you include using {{#partial “field2Override” }}OverrideWith{{/partial}} notation. We show examples of this in the file aruba-delivery-model-using-advanced-template-features.xlsx. See the handlebars.java and handlebars.js websites for more information on how template embedding and partials work.
By default the template with the name ‘job’ will be used for jobs, ‘replenishJob’ for replenishment jobs, ‘vehicle’ for vehicles, ‘configuration’ for configuration, etc. You can have different templates for different jobs or vehicles though. In aruba-delivery-model-using-advanced-template-features.xlsx the jobs sheet has an extra column template. Some of the jobs have a value ‘Pick’ under template and some don’t:
| id | latitude | longitude | quantity | stopSecs | template |
|---|---|---|---|---|---|
| Cust1 | 12.5530 | -70.0422 | 1 | 120 | Pick |
| Cust2 | 12.5095 | -69.9761 | 2 | 120 |
The jobs with the value ‘Pick’ will use the template ‘jobPick’ and the jobs with no value for template will just use the ‘job’ template. The value in the template column is therefore added to the standard template name for jobs (i.e. ‘job’) and ODL Live then looks for a template with this name ( i.e. ‘job’ + ‘Pick’ gets template with id ‘jobPick’).
6.9.1.6 Built-in helper functions
In the template shown in the earlier section, we had the line:
"durationMillis": {{secs2millis stopSeconds}},This used a built-in function to translate the user field stopSeconds into milliseconds. The following built-in functions are supported:
abs. Gets the absolute value of an input number.
add. Usage “add val1 val2”, “add val1 val2 val3”, etc. Adds the input numbers together.
Add and subtract time functions. These functions include addMillis, addSeconds, addMinutes, addHours, addDays, addWeeks, addMonths, addYears and their subtraction equivalents (i.e. subtractMillis, subtractSeconds etc). They add or subtract time to/from a datetime value, providing that value is parseable by lenientParseDatetime. For example “addMinutes 2022-01-01T00:00 60” adds 60 minutes to 2022-01-01T00:00.
case. Usage “case expression key1 value1”, “case expression key1 value1 key2 value2”, “case expression key1 value1 key2 value2 key3 value3”, etc. Replaces the string expression with the corresponding value if it matches one of the keys.
ceil. Does ceil function of an input number.
configVal. Gets a value from the configuration sheet. Use this to define default values in the configuration sheet which you then use in jobs and vehicles (e.g. default stop time).
Use in template like: “cost”: {{configVal “parkCost”}}
The name of the key in the configuration (e.g. parkCost) must be surrounded by speech marks.
divide. Usage “divide val1 val2”. Returns val1/val2.
equals. Only works for numbers. Usage “equals field value”, return 1 if the field is equal to the value.
floor. Does floor function of an input number.
ge. Usage “ge fieldname value”, returns 1 if the field is greater than or equal to the value, 0 otherwise. Fieldname can also be a chained expression.
gt. Usage “gt fieldname value”, returns 1 if the field is greater than value, 0 otherwise.
ifThenElse. Usage “ifThenElse expression1 expression2 expression3”, return expression2 if expression1 is true, otherwise returns expression3. Expression1 is true if its value is “true”, “yes” or 1. ifThenElse can be combined with functions le, lt etc, e.g. “ifThenElse (ge fieldname 10) 100 10”.
le. Usage “le fieldname value”, returns 1 if the field is less than or equal to the value, 0 otherwise.
lenientParseDatetime. Parses a datetime in a ‘lenient’ manner. It will parse datetimes like “2022-12-21T22:08:07.918”, “2022/12/21T22:08”, “2022/12/07 22:08” etc. Usage “parseDatetime datetimeval”. Unlike the parseDatetime function, you don’t pass a format into lenientParseDatetime.
lt. Usage “lt fieldname value”, returns 1 if the field is less than value, 0 otherwise.
local2Utc. Converts a local datetime into UTC using the value of sourceTimezone4TimeWindows from the configuration.
max. Usage “max val1 val2”, “max val1 val2 val3”, etc. Returns the maximum of the input numbers.
miles2km. Converts miles to km.
min. Usage “min val1 val2”, “min val1 val2 val3”, etc. Returns the minimum of the input numbers.
mins2millis. Converts an input number in minutes into milliseconds.
multiply. Usage “multiply val1 val2”, “multiply val1 val2 val3”, etc. Multiplies the input numbers together.
odlStudioTime2millis. Converts an ODL Studio format time into milliseconds, e.g. 10:42:03 is converted into $(10 ) + (42 ) + (3 ).
parseDatetime. Parses an input datetime using the format provided and returns a ODL Live format datetime (ODL Live uses ISO-8601 format datetimes).
The parseDatetime should be used in a template as follows, where timeFieldToBeSet is the field that’s set in the resulting object, timeValueFromExcel is the value from the Excel and “dd/MM/yyyy H:mm:ss” is a datetime formatter defined according to these rules used for the Java DateTimeFormatter.ofPattern method:
“timeFieldToBeSet”: “{{parseDatetime timeValueFromExcel”dd/MM/yyyy H:mm:ss”}}”
parseDatetime can be used with the addMinutes function as in the following example. Here parseDatetime is being called within addMinutes using handlebars subexpressions, where the call to parseDatetime is surrounded by normal brackets (…) not curly braces {…}. We are adding 23 minutes to the time value from the Excel.
{ “timeFieldToBeSet”: “{{addMinutes (parseDatetime timeValueFromExcel”dd/MM/yyyy H:mm”) 23}}” }
pow. Usage “pow a b”, returns a raised to the power b.
replaceAll. Usage “replaceAll expression1 expression2 expression3”. Replaces all occurrences in expression1 of the string expression2 with the string expression3.
round. Rounds an input number.
secs2millis. Converts seconds to milliseconds.
sqrt. Does sqrt of an input number.
subtract. Usage “subtract val1 val2”. Returns val1 − val2.
6.9.2 json2Template - using raw JSON as a template (easier to edit!)
The example template in the previous section has template fields with curly braces {{...}} embedded directly in the JSON, for example:
"quantities": [
{{quantity}}
],When you use curly braces like this, it’s no longer valid JSON and you can no longer edit the template JSON in a JSON editor like JSON Editor online, which makes creating the template harder. To get around this limitation, you can instead use a template which is pure raw JSON (with no curly braces) and define a separate section below the JSON called json2Template, which defines how the fields in the JSON map to template fields. Using json2Template you can therefore create a template by copying-and-pasting an example job or vehicle from a normal JSON model. We use json2Template in the following example template:
# job
{
"quantities": [
1
],
"stops": [
{
"type": "DELIVER",
"durationMillis": 120000,
"coordinate": {
"latitude": 12.5530142955238,
"longitude": -70.0422316047763
},
"_id": "Customer1"
}
],
"_id": "Customer1"
}
## json2Template
quantities[0]=quantity
stops[0].durationMillis=secs2millis stopSeconds
stops[0].coordinate.latitude=latitude
stops[0].coordinate.longitude=longitude
*._id=idThe JSON under the ‘# job’ heading is pure JSON which can be edited in any JSON editor. The key values under the section ‘# json2Template’ basically define a find-and-replace where the key on the left is used to find a field in the JSON and the value on the right is used to replace it. The example template above will therefore be transformed by ODL Live into the following template below:
# job
{
"quantities": [
{{quantity}}
],
"stops": [
{
"type": "DELIVER",
"durationMillis": {{secs2millis stopSeconds}},
"coordinate": {
"latitude": {{latitude}},
"longitude": {{longitude}}
},
"_id": "{{id}}"
}
],
"_id": "{{id}}"
}The two examples are therefore equivalent. ODL Live will automatically add the curly braces {{...}} around the replace value on the right, so you don’t need to include them in the replace value. If curly braces are already present in the replace value, ODL Live won’t add them twice. So if we have an entry in json2Template like follows:
definition.start._id=Start{{id}}which is applied to the following raw JSON template:
# vehicle
{
"definition": {
"start": {
"_id": "StartBigVan1"
}
}ODL Live will transform it into the following template using find-and-replace:
# vehicle
{
"definition": {
"start": {
"_id": "Start{{id}}"
}
}This helps for cases where you want to include a fixed text (i.e. ‘Start’) before the field value (i.e. ‘{{id}}’) read from the Excel.
ODL Live will also automatically handle speech marks when they need to surround a string field. json2Template also supports wildcards, so you can write a template onto several fields at once. In the job example, this json2Template entry:
*._id=idactually replaces two fields in the input JSON, job._id and job.stops[0]._id. It will replace any ’_id’ field. Wildcards also work in arrays, for example:
stops[0].coordinate.latitude=latitude sets the latitude in the job’s 1st stop (the first index in the array is always 0, not 1 following the convention common to most programming languages).
stops[1].coordinate.latitude=latitude sets the latitude in the job’s 2nd stop.
stops[*].coordinate.latitude=latitude sets the latitude in all stops in the job.
Note that if you use the json2Template section, you cannot use curly braces {{...}} inside the template JSON itself, the template JSON must be pure valid JSON or ODL Live will report an error.
The template walkthroughs zip found at:
supporting-data-for-docs\walkthroughs\templates.ziphas example .odlt and .xlsx files using json2Template:
aruba-delivery-model-using-json2Template.odlt
aruba-delivery-model-using-json2Template.xlsx
Some JSON editors can also use JSON schemas which describe the allowed fields within a JSON document. We include JSON schemas for the main ODL Live json objects in:
supporting-data-for-docs\walkthroughs\templates.zip\templates\json-schemasThe command line also has a helper function -tmplPrintApplyJson2Template which takes templates using a json2Template section, does the find-and-replace and prints out the result. This works with an .xlsx file with a templates sheet or an .odlt file, for example:
java -jar odl.live.commandline.jar -setLicence "your-licence-key" -tmplPrintApplyJson2Template "aruba-delivery-model-using-json2Template.odlt"6.9.2.1 Inheritance and calling templates from templates with json2Template
Using json2Template you can have a base template and inherit from it. You can also use handlebars’s partials functionality to embed a template within another template. The example model nemt-soft-rules-model.xlsx in the following directory uses both of these functions to reduce duplication of JSON:
supporting-data-for-docs\example-models\next-day-non-emergency-patient-transportation-soft-rulesSee the readme.html in this directory for more details on this model. Here’s two example templates from it:
# basicJob
{
"breakAllowedBetweenStops" : false,
"quantities": [],
"onboardTimePenalty": {},
"stops": [{},{}],
"_id": ""
}
## json2Template
*._id ={{originalVal}}{{Id}}
quantities={{> quantitiesTemplate}}
onboardTimePenalty={{> onboardTemplate }}
# jobTargetDestTime extends basicJob
stops[0]={{> pickupStop }}
stops[1]={{> dropoffStopWithTW }} The basicJob template defines a few fields and also has a json2Template section which sets the existing fields in the json to either (a) a value or (b) another template, using handlebars’s partial functionality where {{> templateName }} includes a template called ‘templateName’. The templates referenced by the partials (quantitiesTemplate, onboardTemplate, pickupStop, dropoffStopWithTW) are included at other points in the templates sheet.
The jobTargetDestTime template then inherits from the basicJob template using the extends keyword. Templates which extend another template cannot have any JSON defined in them, they can only have field=value statements from the json2Template section, except they don’t need to include the json2Template header, as the entire template is assumed to be json2Template statements. In the field=value statements, the fieldnames should already be included in the template we’re extending or one of its ancestors.
6.9.2.2 Using _id field in arrays with json2Template
ODL Live’s standard identifier field is called _id, and is used in many objects (vehicles, jobs, stops). You can use the name of an object’s _id inside an array instead of a number. For example, in the json2Template section, the following expression,
*.stops["MyStop1"].name=blahwill match all stops with their _id field equal to MyStop1 in any array called stops. So it would match the stop object in the following job object:
{
"stops": [
{
"type": "DELIVER",
"coordinate": {
"latitude": 0.0,
"longitude": 0.0
},
"_id": "MyStop1"
}
],
"_id": "Job1"
}6.9.2.3 Accessing original template value when using json2Template
If you are using json2Template, you can use the value {{originalVal}} inside the replace value to access the original value of the json node you’re replacing.
For example, assume we have the following json2Template,
## json2Template
*._id={{originalVal}}_{{myId}}
*.jobIds[*]={{myId}}-{{originalVal}}
and an example input job object with field myId set to blah. This id field,
"_id" : "LineHaul2Customer"is turned into this id field,
"_id" : "LineHaul2Customer_blah"and this array,
[
{
"jobIds": [
"LineHaul2SortCentre1",
"SortCentre1ToCustomer"
]
},
{
"jobIds": [
"LineHaul2SortCentre2",
"SortCentre2ToCustomer"
]
},
{
"jobIds": [
"LineHaul2Customer"
]
}
]is turned into this array,
[
{
"jobIds": [
"blah-LineHaul2SortCentre1",
"blah-SortCentre1ToCustomer"
]
},
{
"jobIds": [
"blah-LineHaul2SortCentre2",
"blah-SortCentre2ToCustomer"
]
},
{
"jobIds": [
"blah-LineHaul2Customer"
]
}
]The tag {{originalVal}} can only be used within a json2Template section, using it anywhere else will produce an error. {{originalVal}} should not contain any spaces.
6.9.3 Outputting the solution in an Excel spreadsheet
ODL Live can also output a solution as an Excel. The solution Excel has the following four sheets:
SolutionDetails. Overview of entire solution.
RouteDetails. Overview of each route, e.g. total KM, number of stops etc.
StopDetails. List of each stop in each route together with times.
UnassignedJobs. List of unassigned job ids together with codes (where available) indicating why there were unassigned.
You can access the solution Excel in a number of ways:
In the software developer’s dashboard you can download the solution Excel for both main endpoint models and static queue models.
GET your-base-url/models/your-model-id/optimiserstate/solutionexcel downloads the solution Excel for a model on the main endpoint.
GET your-base-url/modeltypes/completedstatic/your-model-id/solutionexcel downloads the solution Excel for a completed static model.
The command line command -rmx will generate an Excel output instead of the plan.json output generated by the -rm command.
The -rmx command acts exactly the same as -rm and takes the same inputs. The following example shows it reading a model from the file ‘inputModel.xlsx’ (using a template) and outputting the solution Excel to ‘outputPlan’:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -tmplLoad "templates1.odlt" -tmplLoad "templates2.odlt" -rmSetMaxMillis 600000 -rmSetMaxItWithoutImprove 50 -rmx inputModel.xlsx outputPlan.xlsxBy default the times in the Excel will be UTC however you can setup your model to export ETAs in a different timezone instead. The example Excel aruba-delivery-model-using-advanced-template-features.xlsx (see section on templates), sets the model up to export times in the timezone defined in the sourceTimezone4TimeWindows value in the configuration sheet.
There is also an extra command to set output Excel file to be produced together with JSON file, and it should be used before -rm command. Command is: -rmSetOutputExcel yourExcelFileName.xlxs where yourExcelFileName.xlxs represents the Excel file to be created, and it could be used with and without “” around file name (so both yourExcelFileName.xlxs and “yourExcelFileName.xlxs” would be valid).
Together with (but before) -rm command it would be like this, for example:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -rmSetOutputExcel yourExcelFileName.xlxs -rm inputModel.json outputPlan.jsonIn this way, after reading and solving the problem in inputModel.json, solution would be presented in two separate Excel and JSON files.
6.9.4 Customising Excel output
6.9.4.1 Including user-set properties with the stop fields
The model ‘1-job-model-with-properties.json’ in the directory ‘supporting-data-for-docs\example-models\custom-fields-in-excel-report’ contains only a single job which has custom properties on the stop object, named ‘hello’, ‘there’ and ‘world’. Here is the job JSON:
{
"quantities": [
1
],
"stops": [
{
"properties": {
"hello": "apple",
"there": "banana",
"world": "peach"
},
"type": "DELIVER",
"durationMillis": 3600000,
"coordinate": {
"latitude": 51.5416,
"longitude": -0.1462
},
"_id": "d1"
}
],
"_id": "j1"
}
You can see these custom properties in the solution Excel if you set the output fields for the stopsDetails table explicitly by adding stopField parameters to the URL. To demonstrate this, firstly PUT the model ‘1-job-model-with-properties.json’ to the main endpoint, giving it an ID of ‘demo’. Then try calling GET on the following URL in your browser to download the Excel:
http://localhost:8080/models/demo/optimiserstate/solutionexcel?stopField=Vehicle&stopField=JobId&stopField=StopId&stopField=StopType&stopField=properties.hello&stopField=properties.there&stopField=properties.worldIf you copy-paste this URL from the pdf, it will add extra spaces that corrupt the URL. However the URL is also included in the readme.txt in the same directory as the model, so you can safely copy it from there.
If you include one or more stopField parameters in the URL, then only the fields you specify with stopField will be included in the stopDetails Excel sheet (i.e. stopField parameters replace the original output fields). The stopFields will be shown in the order you specify in the URL. You can set a stopField equal to either (a) a field from the original stopDetails sheet or (b) a property of the stop.
The original fields available from the stopDetails sheet are Vehicle, JobId, StopId, StopType, OpenTime, LateTime, CloseTime, Address, ArriveTime, StartTime, CompleteTime, LeaveAfterTime, Latitude, Longitude, PlanCumulativeKM.
If you use a property, then you should set stopField equal to properties.PROPERTY_NAME.
We use a mix of both of these in the example URL.
6.9.4.1.1 Enabling user-property fields via the CommandLine
It is also possible to use same logic and set custom stop field names via CommandLine. The command accepts one String which is name of new custom field, but multiple consecutive commands needs to be run in order to collect multiple new custom fields, and they would be added into StopDetails sheet in order of the commands that created them. This command is:
-rmSetStopField "fieldName" It can be used consecutively to set multiple new field names:
-rmSetStopField "fieldName1" -rmSetStopField "fieldName2" -rmSetStopField "fieldName3"But this command must be used in two combinations with other commands, as explained below.
1st case is to use it together with regular command which reads model.json, but where we additionally set output Excel file as well with appropriate command. In this case new command must come before both of them:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -rmSetStopField "fieldName1" -rmSetStopField "fieldName2" -rmSetOutputExcel "nameOfExcelFile" -rm inputModel.json outputPlan.jsonThe above command would create Excel solution file as well and its StopDetails sheet data would only consist of 2 Columns with names “fieldName1” and “fieldName2”. Original stop field names would be overwritten.
2nd case is to use it with command which automatically creates Excel file as output result and not JSON:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -rmSetStopField "fieldName1" -rmSetStopField "fieldName2" -rmx inputModel.xlsx outputPlan.xlsxThe ending result would be same as related to custom field names in Excel file.
User can easily test this command using same example model “1-job-model-with-properties.json” (found in supporting-data-for-docs\example-models\custom-fields-in-excel-report) and same Stop fields set as in above example with URL, with same results.
1st case example:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -rmSetStopField "Vehicle" -rmSetStopField "JobId" -rmSetStopField "StopId" -rmSetStopField "StopType" -rmSetStopField "properties.hello" -rmSetStopField "properties.there" -rmSetStopField "properties.world" -rmSetOutputExcel "nameOfExcelFile" -rm "1-job-model-with-properties.json" outputPlan.json2nd case example:
java -Xmx4G -jar odl.live.commandline.jar -setLicence "your-licence-key" -rmSetStopField "Vehicle" -rmSetStopField "JobId" -rmSetStopField "StopId" -rmSetStopField "StopType" -rmSetStopField "properties.hello" -rmSetStopField "properties.there" -rmSetStopField "properties.world" -rmx "1-job-model-with-properties.json" nameOfExcelFile.xlsx6.9.4.2 Setting Excel output fields in the model configuration
The following directory contains an example model which sets its fields for the three main output sheets via a configuration stored in the model itself:
supporting-data-for-docs\example-models\next-day-non-emergency-patient-transportation-soft-rulesThe model is defined in the Excel file nemt-soft-rules-model.xlsx and the output fields are defined in the template sheet of the Excel. We can also look at the definitions of the output fields in the file balanced-json-model.json, which is the Excel data after the templates have been applied to turn it into ODL Live’s native JSON format.
We have a JSON structure like this:
{
"configuration": {
"reporting": {
"tabularOutputFields": {
"stopDetailsSheet": [],
"routeDetailsSheet": [],
"solutionDetailsSheet": []
}
}
}
}If the stopDetailsSheet, routeDetailsSheet or solutionDetailsSheet arrays are present, they replace the fields in their respective output sheet. If they are not present the sheet remains unchanged.
Here we have a simple configuration:
{
"configuration": {
"reporting": {
"tabularOutputFields": {
"stopDetailsSheet": [
{ "source": "Vehicle"},
{ "source": "StopId" }
]
}
}
}
}where the stopDetails sheet would just include the original Vehicle and StopId fields but no other fields. If the input stop object had a property called ‘colour’ and we wanted to also include this as a field, we would include an element in the array with source=properties.colour.
Here is a more complex element in the stopDetailsSheet array, in the model balanced-json-model.json:
{
"columnName": "TravelCost",
"source": "json.enrouteOptCosts.TRAVEL",
"defaultValueIfNull": "0",
"decimalFormatPattern": "#.#####"
}Let’s look at the individual fields:
columnName - this is just the output fieldname to use (it will be set to the source if no columnName is included).
source - this says where the field value comes from. We have json.enrouteOptCosts.TRAVEL. The json. prefix tells ODL Live to read this from the planned stop object (or vehicle plan end point object), the enrouteOptCosts. says to read from the enrouteOptCosts object within the plan object, and TRAVEL is the field to read.
defaultValueIfNull - a default value to show in the output Excel if the field is not found in the JSON or is null.
decimalFormatPattern - how to format the field. The format string is the pattern string used by Java 8’s DecimalFormat class.
Here’s another example from the model, this time for the SolutionDetails sheet:
{
"columnName": "OnBoardTooLongHours",
"source": "json.statistics.totalTimes.onBoardSecondsOverDirectBasedLimit",
"defaultValueIfNull": "0",
"divideBy": 3600.0,
"decimalFormatPattern": "#.#####"
}
Here we introduce the field divideBy, which divides the output number (here we’re turning a number in seconds into a number in hours). multiplyBy is also supported.
Some fields appear in different places for the planned stops and planned end point objects. We can get around this by first checking the source location and if this is null, then checking other sources defined in altSources as follows:
{
"columnName": "LatenessHours",
"source": "json.timeEstimates.latenessHours",
"altSources": [
"json.latenessHours"
]
} 6.10 Optimisation objective
6.10.1 Standard or lexicographic objective
The standard optimiser objective minimises the number of unassigned jobs and then the total cost, where cost is a weighted sum of all the different cost types over all the different routes in the model. Instead of having a single monolithic cost value, you can also split the cost objective into multiple ordered values using lexicographic optimisation, which can simplify tuning.
The following example model demonstrates the optimiser configured for lexicographic optimisation, where we have different optimisation objectives and some objectives are defined to be more important than others:
supporting-data-for-docs\example-models\lexicographic-objectiveLexicographic optimisation can make it simpler to tune a model, as if you want one type of cost to be more important than another, you don’t have to worry about setting specific cost weights to ensure the more important cost always has a bigger value. So given two objectives in the order [A, B] even a tiny improvement in objective A is better than any improvement in B.
We configure the objectives in the object
model.configuration.problem.objectives (if you omit this
object, we just use standard optimisation instead). Here’s the
objectives from the example model:
"objective" : {
"lexicographicObjectives" : [ {
"costTypesToSum" : [ "LATENESS" ]
}, {
"costTypesToSum" : [ "VEHICLE_FIXED" ]
}, {
"costTypesToSum" : [ "ALL_OTHERS" ]
} ]
}
Here we are saying that lateness (e.g. late jobs, late returning vehicles) is more important than any other objective, then vehicle fixed cost (which is based on the number of vehicles used) is the next most important and then all other objectives are taken into account. So the optimiser will always choose the solution with least lateness. Given two solutions with the same lateness, it will then always choose the solution with least vehicle cost. If two solutions have the same lateness and vehicles cost, it will then consider the weighted sum of all other cost types.
The types of costs in
lexicographicObjectives.costTypesToSum must follow certain
rules (or ODL Live will throw an error):
A cost type cannot be repeated.
The cost types ALL_OTHERS - meaning all other cost types - must be included somewhere in
lexicographicObjectives.Only the following cost types are allowed:
- AFTER_DISPATCHES_DIST_AT_STOP
- AFTER_TRAVEL_CUSTOM_FORMULA
- CENTERING
- EARLY_REPLENISH
- FINISH_LAST_JOB_LATENESS
- FIXED_JOB_COST_GROUP
- FULLNESS
- INCOMPATIBLE_JOBS
- JOB_PATTERN
- LATENESS
- MAX_SEPARATION
- MAX_WORK_TIME
- ON_BOARD_TIME
- PER_STOP_COST
- REPLENISH_FILL
- SERVICE_RADIUS
- SERVICE_TIME
- SHARED_STOP_COST
- SOFT_CAPACITY
- TOTAL_DRIVE_DISTANCE
- TOTAL_DRIVE_TIME
- TRAVEL
- UNASSIGNED_COST
- VEHICLE_FIXED
- VEHICLE_VALS_COST_FUNC
- WAITING
- WORK_TIME_EXCL_WAIT
- WRONG_DIRECTION
costTypesToSum is an array and so it can contain
multiple cost types, e.g. the following would minimise the sum of
lateness cost and onboard time penalty first:
"objective" : {
"lexicographicObjectives" : [ {
"costTypesToSum" : [ "LATENESS,ON_BOARD_TIME" ]
}, {
"costTypesToSum" : [ "VEHICLE_FIXED" ]
}, {
"costTypesToSum" : [ "ALL_OTHERS" ]
} ]
}