8 Job level features
The following subsections detail various advanced features you can enable for modelling jobs. If you’re looking for a feature and you don’t find it in this section, it’s likely you can implement it with user functions instead.
8.1 Fixed cost group for jobs
Use case. The job fixed cost group encourages the optimiser to place a group of jobs on the same vehicle. It is a ‘soft rule’ - if the optimiser thinks it is cheaper to put jobs in the same group onto different vehicles, it will still do this. If you need to force the optimiser to put multiple jobs on the same vehicle, see custom jobs. The fixed cost group doesn’t care where these jobs appear in the vehicle, it only encourages the jobs to appear on the same vehicle and not at the same position. If instead you want to encourage the optimiser to include jobs together on a vehicle and serve the jobs at the same time (i.e. consecutively) see stop parking cost or from stop rules.
How to use. The supporting-data-for-docs has the following example model:
supporting-data-for-docs\example-models\job-fixed-cost-group\job-fixed-cost-group.jsonIn this model we define a fixed cost for a group of jobs. This cost is added only once to a vehicle (per job group) whenever one or more stops in the group is assigned to the vehicle. In other words, the cost for the vehicle is the same if 1, 2 or 3 jobs in the same fixed cost group are added to the vehicle.
The cost acts as a penalty if jobs in the same group are added to different vehicles, e.g. assume job group “1” has a penalty of 1000. If all 3 jobs in job group “1” are added to the same vehicle, only the penalty of 1000 is added to the total solution cost. If the 3 jobs in group “1” are assigned to 2 vehicles, a penalty of 2000 is added to the solution cost, and a penalty of 3000 is added if they’re added to 3 different vehicles. The penalty is defined in job.fixedCostGroup like follows, and should be the equal for all jobs in a group:
"fixedCostGroup" : {
"id" : "1",
"cost" : 1000.0
},id is the identifier of the cost group and can be any string value you want. If you set different cost values for different jobs in the same group, ODL Live will simply take the maximum out of all cost values for the group.
8.2 Incompatible jobs
Incompatible jobs are not currently realtime compatible and will not take account of dispatched jobs.
If the incompatible jobs functionality described here is not flexible enough, you might consider implementing your own logic using a sequence based state user function (SEQSTATE). SEQSTATE functions are also evaluated correctly when stops have been dispatched, i.e. are realtime compatible.
The incompatible jobs functionality lets you set that one group of jobs cannot be on the same route as another group of jobs. It also lets you set that the two groups cannot be together on non-empty subsections of the route, i.e. given a route of pickup->delivery jobs Pickup1, Pickup2, Dropoff1, Dropoff2, Pickup3, Dropoff3 we have two non-empty subsections (Pickup1, Pickup2, Dropoff1, Dropoff2) and (Pickup3, Dropoff3) and we could place a rule that operates on these subsections instead of the entire route. The incompatible jobs functionality doesn’t currently let you define that two groups of jobs can’t be on-board at the exact same time, it only checks the route or subroute level (see the incompatible quantities section instead if you want to do this).
To use the incompatible jobs, you must firstly place jobs into job groups, by adding the group id to the array job.jobGroupIds. The following JSON shows a pickup-delivery job which is added to job group ‘a’. Job group ids can be any string you want:
{
"jobGroupIds": ["a"],
"stops": [
{
"type": "SHIPMENT_PICKUP",
"coordinate": {
"latitude": 51.5073,"longitude": -0.1657
},
"_id": "P0"
},
{
"type": "SHIPMENT_DELIVERY",
"coordinate": {
"latitude": 52.4862,"longitude": -1.8904
},
"_id": "D0"
}
],
"_id": "J0"
}You must then add the following structure to model.configuration.problem.incompatibleJobGroupRules which defines the rules:
{
"_id": "myModelId",
"data": {
"jobs": [],
"vehicles": []
},
"configuration": {
"problem": {
"incompatibleJobGroupRules": [
{
"jobGroupIdsA": [
"a"
],
"jobGroupIdsB": [
"b"
],
"prohibited": true,
"ruleType": "WHOLE_ROUTE"
}
]
}
}
}incompatibleJobGroupRules is an array, so you can have multiple rules defined. Each element in incompatibleJobGroupRules supports the following fields:
jobGroupIdsA. First array of job group ids. At least one job group id in the first array and at least one in the second array must match jobs in the route or subsection, for the rule to be activated.
jobGroupIdsB. Second array of job group ids.
prohibited. Set to true if this is a hard rule that should not be broken. Otherwise leave field out or set to false.
cost. Set to a numerical value (e.g. 10.0) if you want this to be a hard rule which can broken, but which applies a cost if it’s broken, so the optimiser will try to avoid breaking the rule if this minimises total solution cost. If prohibited=true then cost is ignored.
ruleType. Valid values of this are WHOLE_ROUTE or NON_EMPTY_SECTION.
For self-hosting subscribers the supporting-data-for-docs directory has example models in the subdirectory supporting-data-for-docs\example-models\incompatible-job-groups. These example models are 5 different versions of the same model with:
2 pickup delivery jobs (P0->D0 and P1->D1), one in group ‘a’ and the other in group ‘b’.
Both pickups are at the vehicle depot and both deliveries are at the same delivery location, so the optimal route is P0,P1,D0,D1 (or equivalently P1,P0,D1,D0 or P1,P0,D0,D1 or P0,P1,D1,D0, all are equally good in terms of solution cost).
To get the different versions we apply either whole route or section rules, and soft or hard rules. This is a summary of the models:
___________________________________________________________________________________
Filename Stop seq. Cost Cost breakdown
___________________________________________________________________________________
No rule.json P1,P0,D1,D0 3.992 TRAVEL=3.992
Rule=WHOLE_ROUTE.json P1,D1 3.992 TRAVEL=3.992
Rule=NON_EMPTY_SECTION.json P0,D0,P1,D1 7.983 TRAVEL=7.983
Rule=NON_EMPTY_SECTION rule.cost=3.json P1,P0,D1,D0 6.992 INCOMPATIBLE_JOBS=3
TRAVEL=3.992
Rule=NON_EMPTY_SECTION rule.cost=5.json P1,D1,P0,D0 7.983 TRAVEL=7.983
___________________________________________________________________________________Looking at each model in-turn:
Model No rule.json has no rule set inside it, so we get the optimal route P1,P0,D1,D0 with the minimum cost 3.992.
Model ‘Rule=WHOLE_ROUTE.json’ has the hard rule applied to the whole route, which means only 1 job of the 2 jobs can be served without breaking the rule, and so 1 job remains unassigned.
Model ‘Rule=NON_EMPTY_SECTION.json’ has the hard rule applied to each section instead. Both jobs can therefore be served by doing one job first and then the other, so the vehicle is empty after dropping off the first job and before doing the second. The route therefore has two non-empty sections - (P0,D0) and (P1,D1) - with one section for each job, and no rule is broken. This has twice the travel cost of the ‘No rule.json’ model as the vehicle has to go out from the depot and come back twice.
Model ‘Rule=NON_EMPTY_SECTION rule.cost=3.json’ uses a soft rule instead as prohibited is not set, and cost is set to 3. As the travel cost of going out from the depot and returning is 3.992 and the cost of breaking the rule is only 3, the optimiser decides its cheaper to break the rule and we get P1,D1,P0,D0.
Model ‘Rule=NON_EMPTY_SECTION rule.cost=5.json’ has the cost of breaking the rule set to 5, which is more expensive than going out from the depot and coming back an extra time. As a result, the rule is not broken in this model and we get P1,D1,P0,D0.
8.3 Job patterns (e.g. 2-echelon)
Job patterns allow you to setup different patterns of jobs and the optimiser will choose the best pattern - e.g. the optimiser chooses between ‘do jobs A, B and C’ or ‘do jobs D and E’. Job patterns let the optimiser model more types of vehicle routing problems including periodic problems and 2-echelon vehicle routing problems.
The supporting-data-for-docs has a small example jobs patterns model here:
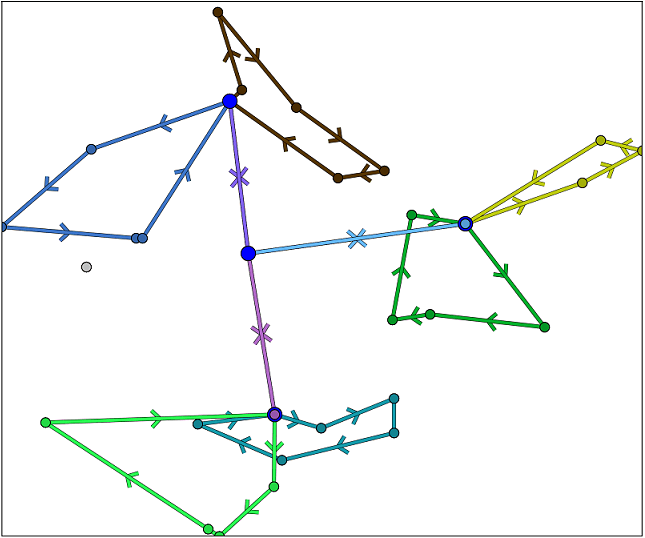
supporting-data-for-docs\example-models\simple-2-echelon\simple2Echelon.jsonThis model uses straight line distances so you don’t need to setup the road network data. Loosely speaking, 2-echelon vehicle routing problems involve delivering items from a central depot, to satellite depots and then from the satellite depots to the end delivery locations. The optimiser must (a) choose the satellite depot for a delivery to pass through, (b) optimise the truck routes from the central depot to the satellite depots and (c) optimise the last mile routes from the satellite depots to the end customers. The model file simple2Echelon.json contains a small example 2-echelon problem with only 25 jobs. It generates a set of routes like the following image:
To setup a ‘job patterns’ job, these are the 3 main steps:
Create a top level container job. All the jobs within the job pattern will be inside this container job.
Add the individual jobs within the patterns to the container job’s altJobs array (the altJobs array is also used when we define alternative jobs).
Add the pattern objects which describe the job patterns to the container job’s jobPatterns array.
The following JSON shows a single job from the simple2Echelon.json model:
{
"altJobs": [
{
"quantities": [1],
"requiredSkills": ["trunk"],
"stops": [{
"type": "DELIVER",
"coordinate": {"latitude": 49.38392052351336,"longitude": 2.0454280701658423},
"_id": "J0ToSat0"
}],
"_id": "J0ToSat0"
},
{
"quantities": [1],
"requiredSkills": ["sat0"],
"stops": [{
"type": "DELIVER",
"coordinate": {"latitude": 48.70471903113105,"longitude": 7.740622302308033},
"_id": "J0Sat0ToEnd"
}],
"_id": "J0Sat0ToEnd"
},
{
"quantities": [1],
"requiredSkills": ["trunk"],
"stops": [{
"type": "DELIVER",
"coordinate": {"latitude": 47.10166307135962,"longitude": 0.06788900766584227
},
"_id": "J0ToSat1"
}],
"_id": "J0ToSat1"
},
{
"quantities": [1],
"requiredSkills": ["sat1"],
"stops": [{
"type": "DELIVER",
"coordinate": {"latitude": 48.70471903113105,"longitude": 7.740622302308033},
"_id": "J0Sat1ToEnd"
}],
"_id": "J0Sat1ToEnd"
},
{
"quantities": [1],
"requiredSkills": ["trunk"],
"stops": [{
"type": "DELIVER",
"coordinate": {"latitude": 45.05968084342003,"longitude": 2.6606624451658423
},
"_id": "J0ToSat2"
}],
"_id": "J0ToSat2"
},
{
"quantities": [1],
"requiredSkills": ["sat2"],
"stops": [{
"type": "DELIVER",
"coordinate": {"latitude": 48.70471903113105,"longitude": 7.740622302308033},
"_id": "J0Sat2ToEnd"
} ],
"_id": "J0Sat2ToEnd"
},
{
"quantities": [1],
"requiredSkills": ["trunk" ],
"stops": [{
"type": "DELIVER",
"coordinate": {"latitude": 47.69657454833933,"longitude": 5.297381195165842},
"_id": "J0ToSat3"
}],
"_id": "J0ToSat3"
},
{
"quantities": [1],
"requiredSkills": ["sat3"],
"stops": [{
"type": "DELIVER",
"coordinate": {"latitude": 48.70471903113105,"longitude": 7.740622302308033},
"_id": "J0Sat3ToEnd"
}],
"_id": "J0Sat3ToEnd"
}
],
"jobPatterns": [
{
"jobIds": ["J0ToSat0","J0Sat0ToEnd"]
},
{
"jobIds": ["J0ToSat1","J0Sat1ToEnd"]
},
{
"jobIds": ["J0ToSat2","J0Sat2ToEnd"]
},
{
"jobIds": ["J0ToSat3","J0Sat3ToEnd"]
}
],
"_id": "J0"
}We have 8 delivery jobs defined in the container job’s altJobs. These alt jobs correspond to:
- Central depot to satellite depot 0 (job J0ToSat0) and satellite depot 0 to end location (job J0Sat0ToEnd).
- Central depot to satellite depot 1 (job J0ToSat1) and satellite depot 1 to end location (job J0Sat1ToEnd).
- Central depot to satellite depot 2 (job J0ToSat2) and satellite depot 2 to end location (job J0Sat2ToEnd).
- Central depot to satellite depot 3 (job J0ToSat3) and satellite depot 3 to end location (job J0Sat3ToEnd).
We’ve used skills to lock down the alt jobs to trunk vehicles (central depot to satellite) or last-mile vehicles (satellite to end destination) appropriately, where the satellite-to-end-location jobs are skill-locked to vehicles starting at the satellite which their corresponding depot-to-satellite job delivered to.
The elements in the jobPatterns array connect the 2 alt jobs going through a satellite using the _id field of each alt job, e.g. the first element in job patterns links J0ToSat0 and J0Sat0ToEnd which go through satellite 0.
{
"jobIds": ["J0ToSat0","J0Sat0ToEnd"]
}The optimiser will choose the best pattern out of the jobPatterns array and load only the jobs in the selected pattern’s jobIds array, the jobs in the other patterns will remain unloaded. In other words the optimiser will only choose the alt jobs from the jobIds array in one pattern.
Each pattern object can have the following fields:
cost - the optimiser cost of serving this pattern (assumed to be zero if this field is omitted).
jobIds - the alt job ids in this pattern.
name - a name field for this pattern. The optimiser does not use the name field, it’s just available if you want to add a note to your JSON to make the structure clearer.
Several other fields which are also used when defining repeating patterns for periodic problems (see later section).
There are several restrictions when using job patterns:
The optimiser will not put multiple jobs in the same pattern on the same route, each job in the selected pattern will go on a different route. For specific problems you may able to get around this restriction by defining the alt job to be a custom job which can have more than 2 stops.
One pattern cannot have jobIds which are a subset of another pattern’s jobIds.
A pattern can only refer to job ids in the container job, not other container jobs.
Realtime modelling is not currently supported for job patterns. The optimiser will not use dispatched events for stops in the pattern, and may throw an error if stops in a job pattern are dispatched.
Top level container jobs and alt jobs must all have unique ids. All stops must have unique ids too.
No support for partially loaded pattern - a job with patterns will either have all stops in its selected pattern assigned or no stops assigned.
8.3.1 Tweaking optimiser search when using job pattern costs
If you have a problem where (a) job patterns within a single job have different fixed costs for each pattern, (e.g. pattern A has cost=0.1, pattern B has cost=0.2), and (b) one job in the pattern can be more efficiently combined in a route with other jobs (e.g. the job(s) in pattern B have lower quantity than the job(s) in pattern A), the optimiser may be too myopic and fail to make the right choice, as it won’t anticipate that the pattern with the higher fixed cost is actually cheaper when you consider other jobs too.
For these cases it is useful to add some noise to the search method, so when the optimiser considers which pattern to choose when inserting a job, on some iterations it will use the fixed pattern cost and others it will ignore it. This randomisation of the search method can improve the resulting plan significantly for certain problems. See the example model JSON in this directory:
supporting-data-for-docs\example-models\job-pattern-cost-discounting-within-searchThis example model is deliberately designed to demonstrate this. Each job has two jobs patterns, where the ‘pool’ alternative job in the 2nd pattern has a fixed cost but the alternative job in the first pattern has no fixed cost:
"jobPatterns" : [ {
"jobIds" : [ "Job0" ]
}, {
"cost" : 1.0E-5,
"jobIds" : [ "PoolJob0" ]
} ],
The pool job has a smaller quantity value, so that several pool jobs can be on-board a vehicle at once but only one non-pool job can be on-board at once. It is therefore cheaper to select the pool jobs, even though they have a higher pattern cost.
In the model:
model.configuration.optimiser.jobPatternCostDiscounting.probabilitySetPatternCosts2Zero was set to 0.5:
"configuration" : {
"optimiser" : {
"jobPatternCostDiscounting" : {
"probabilitySetPatternCosts2Zero" : 0.5
}
},
"timeOverride" : {
....
}
},
This means that during the search method it has a 0.5 probability (i.e. 50% probability) of temporarily ignoring the pattern cost. With probabilitySetPatternCosts2Zero set, this model gives a much better result as the pool jobs are chosen. In contrast when probabilitySetPatternCosts2Zero is not set, the optimiser is too myopic and gives a worse result with only the non-pool jobs chosen.
8.4 Job removal analysis
You can set ODL Live to automatically calculate the impact of removing a job from the current plan. This is useful to answer questions such as “which is a good job to remove to stop my route running late?”. This feature has to be enabled on a per-model basis. In the model configuration object (which contains distances configuration etc.) you should add a new object called “analysis”, as per below:
{
"distances" : {
......
},
"analysis" : {
"singleJobRemoval" : true
},
}Once this is turned on in the configuration and the optimiser has performed an optimisation burst, the lateness removal analysis will be available in the plan object. Note that if the server has rebooted, the optimiser will need to run a burst before this object is available, so if you have turned the analysis on but the analysis doesn’t appear in the plan object, keep repolling every second or so until it appears.
The following JSON shows a plan object with the new analysis object:
{
"vehiclePlans" : [
.... planned routes appear here as normal
],
"statistics" : {
.... statistics appear here as normal
},
"analysis" : {
"jobRemovalAnalysis" : {
"jobsBestFirst" : [ {
"jobId" : "4",
"affectedRoutes" : [ {
"vehicleId" : "v",
"plannedStops" : [
.... Updated times of remaining stops are here....
],
} ],
"estimatedChange" : {
"cost" : -2.1666686666666664,
"latenessSeconds" : 0.0,
"travelSeconds" : -7200.0,
"operationTimeSeconds" : -600.0,
"waitTimeSeconds" : 0.0,
"usedVehicles" : 0
},
"rank" : 0
}, {
"jobId" : "3",
"affectedRoutes" : [ {
.....
} ],
"estimatedChange" : {
.....
},
"rank" : 1
}
]
}
}
}The plan now contains an object called analysis which contains an object called jobRemovalAnalysis. jobRemovalAnalysis has a list jobsBestFirst which contains the effect of removing each job, sorted best first (i.e. greatest cost reduction first). Using the default settings, lateness cost dominates any other costs. Therefore if lateness is present in the planned routes, this list is effectively sorted by “largest lateness reduction first”. Each removal is considered independently of the others - i.e. we calculate the effect of removing job A or removing job B but not the effect of removing both A and B at the same time.
In the jobsBestFirst list, the removal analysis object for each job contains the following key fields / objects:
jobId.
affectedRoutes. This is the list of vehicle routes affected by the removal of the job. Normally this would be only a single route, but in the future ODL Live may support multi-route jobs. The affectedRoutes includes the planned stop objects - so you can retrieve the updated timings for stops on the route from this object.
estimatedChange. This contains useful stats on the affect of the removal - for example latenessSeconds has the change in lateness.
If you have a large model, then the default analysis object in the plan JSON can be quite large, potentially having an impact on network bandwidth. We therefore provide two optional parameters that can be used to filter this object when you GET the plan. These are job-removal-analysis-include-routes and job-removal-analysis-max-jobs. The following example GETs use these:
GET my-base-URL/models/TestModel1/optimiserstate/plan?job-removal-analysis-include-routes=false
GET my-base-URL/models/TestModel1/optimiserstate/plan?job-removal-analysis-max-jobs=5You can also combine both parameters at once by adding them both to the URL, separated by &.
8.5 Locking jobs to vehicles
There are three main ways of locking jobs to vehicles, which have different ‘lock’ strengths:
Weaker lock using skills. You can use skills to lock jobs to vehicles by (a) adding a unique ID to a vehicle’s vehicle.definition.skills array and (b) adding the same ID to a job’s job.requiredSkills array. This will ensure the job can only be assigned to the vehicle. However if not all jobs in the problem can be assigned as there’s not enough vehicle resource, a skill-locked job could be unassigned in-favour of an unlocked job if the optimiser thinks this is cheaper (i.e. skill-locked jobs don’t take priority, although you can setup unassigned costs to get around this).
Strong lock using vehicle lock state. You can set the vehicle’s lock state to include a job’s ID. The job can still become unassigned if assigning it would break a hard constraint, however locked jobs are considered more important than unlocked jobs, and a locked job should not become unassigned in-favour of assigning an unlocked job.
Strongest lock using preloaded stops (only works for single-stop SERVICE jobs). For single-stop SERVICE type jobs you can lock them to a vehicle using preloaded stops. The stops will always be on the vehicle, however if this breaks hard constraints the vehicle will be considered ‘impossible’ and additional jobs will not be added to it.
Vehicle lock state locking also has to be used when you have vehicles serving DELIVER job types that you model in realtime, and so you keep optimising a model after vehicles have left their start depot and need to keep on-board DELIVER jobs assigned to their vehicle. See this next section for more details on how to model locking for depot-based scenarios.
The directory supporting-data-for-docs\example-models\locking-jobs-to-vehicles has an example model example-model-lock-jobs-to-vehicles.json. This model contains simple DELIVER type jobs, like this one:
{
"quantities": [ 1 ],
"stops": [
{
"type": "DELIVER",
"durationMillis": 0,
"coordinate": {
"latitude": 51.55682810601671, "longitude": 0.10038226934439609
},
"_id": "s2"
}
],
"_id": "j2"
}The model contains only a single vehicle object:
{
"definition": {
"start": {
"type": "START_AT_DEPOT",
"coordinate": {
"latitude": 51.5416, "longitude": -0.1462
},
"openTime": "2001-01-01T08:00:00",
"_id": "T9mjqeyFTfWQ-IHyI38ZtA=="
},
"end": {
"type": "RETURN_TO_DEPOT",
"coordinate": {
"latitude": 51.5416, "longitude": -0.1462
},
"closeTime": "2001-01-01T16:00:00",
"_id": "HVXl7KuDQBOxh54FUnnXfg=="
},
"capacities": [ 10 ]
},
"lock": {
"jobLocks": [
{ "jobId": "j15" },
{ "jobId": "j3" },
{ "jobId": "j23" },
{ "jobId": "j2" },
{ "jobId": "j9" }
],
"state": "UNLOCKED"
},
"_id": "v0"
}Each job has a quantity of 1 and vehicle.definition.capacity is set so only 10 jobs can fit on. The vehicle has an object vehicle.lock. The lock object contains 2 fields - an array called jobLocks and a state set to UNLOCKED. The jobLocks array contains a lock object for each job locked to the vehicle, where each job lock object has the single field jobId set to the _id of its job (and not the _id of the locked job’s stop).
The state is set to UNLOCKED because this indicates other jobs can still be added to the vehicle (typically as it hasn’t left the depot yet - the state field is primarily used to prevent DELIVER jobs being assigned to a vehicle after it’s left the depot). For normal job locking (not for depot-based problems) you should always set state to UNLOCKED.
For this example model only 10/25 jobs will be assigned, but the locked jobs will always be included in these 10 assigned jobs as they take priority over the unlocked jobs.
Note that the vehicle lock state does not override hard constraints, vehicle-locked jobs can still be unassigned if they break hard constraints, however they will never be unassigned to allow an unlocked job to be assigned instead. The only exception to this ‘no overriding hard constraints’ rule is for DELIVER type jobs which break the quantities constraints, DELIVER jobs will remain locked to a vehicle even if their quantity sum exceeds the vehicle’s capacity.
Vehicle locks work for different types of jobs (i.e. not just DELIVER jobs) but are not compatible with job patterns.
Rather than setting the lock on the vehicle object, you can also set the lock2VehicleId on the job like in this example job JSON:
{
"stops" : [ {
"type" : "DELIVER",
"coordinate" : {
"latitude" : 51.54792521152047, "longitude" : 0.17358325662114982
},
"_id" : "s0"
} ],
"lock2VehicleId" : "v1",
"_id" : "j0"
}8.5.1 Locking delivery jobs on-board when a vehicle leaves a depot
After an item has been loaded onto a vehicle for delivery and the vehicle has left the depot, clearly the item should be locked to that vehicle within the optimiser plan, as the item is physically sitting on-board the vehicle in real life. The item should therefore not be reassigned to a different vehicle, although the delivery order of on-board items could change (e.g. the 5th delivery might be moved to the 7th delivery if changing conditions made this more efficient). Similarly, it should be impossible to plan more deliveries for the vehicle after it has left the depot, but more collections can still be planned.
8.5.1.1 Automatic locking
The optimiser can be configured to automatically lock a vehicle after a set time, e.g. if loading starts at 6am at a depot, set the optimiser to automatically lock deliveries at 5:50am.
The vehicle definition includes a property lockDeliveriesTime (time in UTC). If this is set, the first optimisation burst after this time automatically creates a lock record within the optimiser state, if the lock doesn’t already exist. As a result:
The vehicle’s planned deliveries are now locked to the vehicle as they are saved in the lock record’s list of locked jobs.
No further deliveries will be planned for the vehicle (i.e. it is considered ‘locked’).
8.5.1.2 Overriding optimiser locks
By design the client cannot clear the vehicle’s lock state within the optimiser using the API (unless they delete the vehicle and re-add it under a different id). This prevents the client and optimiser writing to the same data - which is a key design principle of the data syncing mechanism in ODL Live. There may however be circumstances where you need to override the behaviour of the optimiser lock - e.g. to add an extra delivery after the automatic locking time. You can override the behaviour of the optimiser lock by setting your own lock (of type ODLVehicleLock) on the vehicle object’s lock field. This then overrides the optimiser lock - i.e. a vehicle’s data model lock object takes priority over its optimiser lock object. If the client wants to completely disable the optimiser lock, they should override it and (a) set the state property in ODLVehicleLock to UNLOCKED (currently this state can be UNLOCKED or NO_MORE_DELIVERIES), (b) ensure their overriding ODLVehicleLock object has an empty list of jobs.
To summarise:
The client system and the optimiser never write to the same data / same lock object.
The lock is created by default, even if the client system does nothing.
The optimiser lock can be overridden by the client system.
If the client system doesn’t want to override the optimiser lock, they don’t need to do anything.
The optimiser behaviour is driven by input model data.
8.5.1.3 What happens if a vehicle breaks down?
If a vehicle is deleted from the model (i.e. no longer present in the model), then its optimiser locking state will also be deleted, after the next optimisation burst occurs. This will result in deliveries being reassigned if there is another vehicle available whose delivery state isn’t locked yet. If a vehicle breaks down (e.g. with deliveries on-board), then instead of deleting it you should disable it, by setting its close time window (the hard time window, not the late time window), to the breakdown time or the current time. Alternatively, you could set both its open and close times to an arbitrarily early time before the current (e.g. one year ago). This will prevent any more jobs being planned for the broken-down vehicle but the deliveries currently locked to it will not be automatically rescheduled. These locked deliveries will require manual intervention to sort out.
8.6 On-board time penalty
The on-board penalty allows a penalty cost or a hard limit to be assigned on the amount of time an item is on-board the vehicle. The penalty could be based on (a) an absolute time limit (e.g. 45 minutes), (b) a time limit based on the direct travel time between the pickup and dropoff locations (e.g. no more than 1.5 times the direct travel time) or (c) a combination of both.
On-board limits are relevant to both passenger transport and hot food deliveries. For hot food deliveries, it allows you to model the degradation of food quality on-board the vehicle after it has left the restaurant (e.g. avoid cold burgers and cold fries). The on-board penalty is realtime-compatible, if pickup stops are dispatched and/or completed the penalty is calculated correctly for the delivery time based on the estimated or recorded pickup completion time.
Depending on how your time windows are set on the pickup and dropoff stops, you may need to use pickup delay optimisation with on-board penalties. See this section for more details.
8.6.1 Logic with multiple pickups at the same location
In the case where multiple different orders are being collected consecutively at the same restaurant by the same driver, the on-board penalty is measured from the completion time of the last consecutive stop at the restaurant. This is based on the assumption that the completion time of the last consecutive stop is the time the driver leaves the restaurant and that whilst the food is still inside the restaurant, it can be kept hot. So if pickups P1, P2 and P3 are set to take 3 minutes each, and are collected together in that order at the restaurant, then the on-board penalty for P1 is actually measured from the completion time for P3 (either the predicted completion time or the event if it has occurred). The geocodes (latitudes and longitudes) for the pickup stops must be less than 1 metre apart for them to be considered ‘at the same location’ and this logic to apply.
8.6.2 JSON definition of on-board penalty
On-board penalty times limits are defined using the same type of penalty functions used in various other parts of the ODL Live API. You should therefore read the section on penalty functions before reading this section.
On-board penalties are defined slightly differently if you’re using custom jobs or normal pickup-delivery jobs. The logic used for pickup-delivery still applies to custom jobs, but custom jobs just require a couple more fields (see this section for more details). The following pickup-delivery job has an on-board time penalty.
{
"stops" : [ {
"type" : "SHIPMENT_PICKUP",
"durationMillis" : 60000,
"coordinate" : {
"latitude" : 40.70440673828125,
"longitude" : -74.00933074951172
},
"_id" : "P1"
}, {
"type" : "SHIPMENT_DELIVERY",
"durationMillis" : 180000,
"coordinate" : {
"latitude" : 40.73283004760742,
"longitude" : -74.0078125
},
"_id" : "D1"
} ],
"onboardTimePenalty" : {
"type" : "FROM_LEAVE_LOC",
"hoursPenalty" : [ {
"inclusiveLowerLimit" : 0.25,
"c1" : 1.0,
"join" : "EXACT"
}, {
"inclusiveLowerLimit" : 0.5,
"c2" : 1000.0,
"join" : "EXACT"
}, {
"inclusiveLowerLimit" : 1.0,
"prohibited" : true
} ]
},
"_id" : "Job1"
}The field onboardTimePenalty.hoursPenalty stores the penalty function defining the cost based on how long the item is on-board the vehicle. Following the instructions in section penalty functions, we can view a graph of this penalty function:
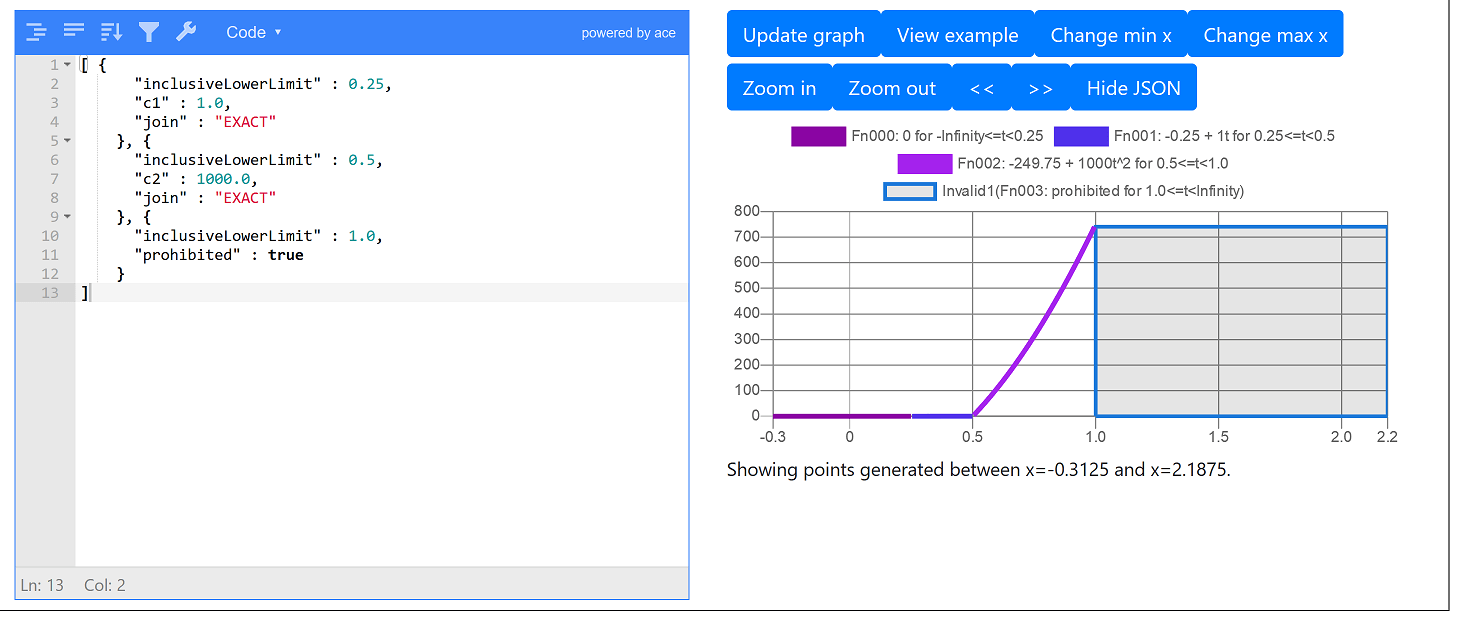
We see the following areas:
If the item is on-board less than 0.25 hours (15 minutes), no penalty cost is defined, This corresponds to the 1st purple region on the graph where x < 0.25.
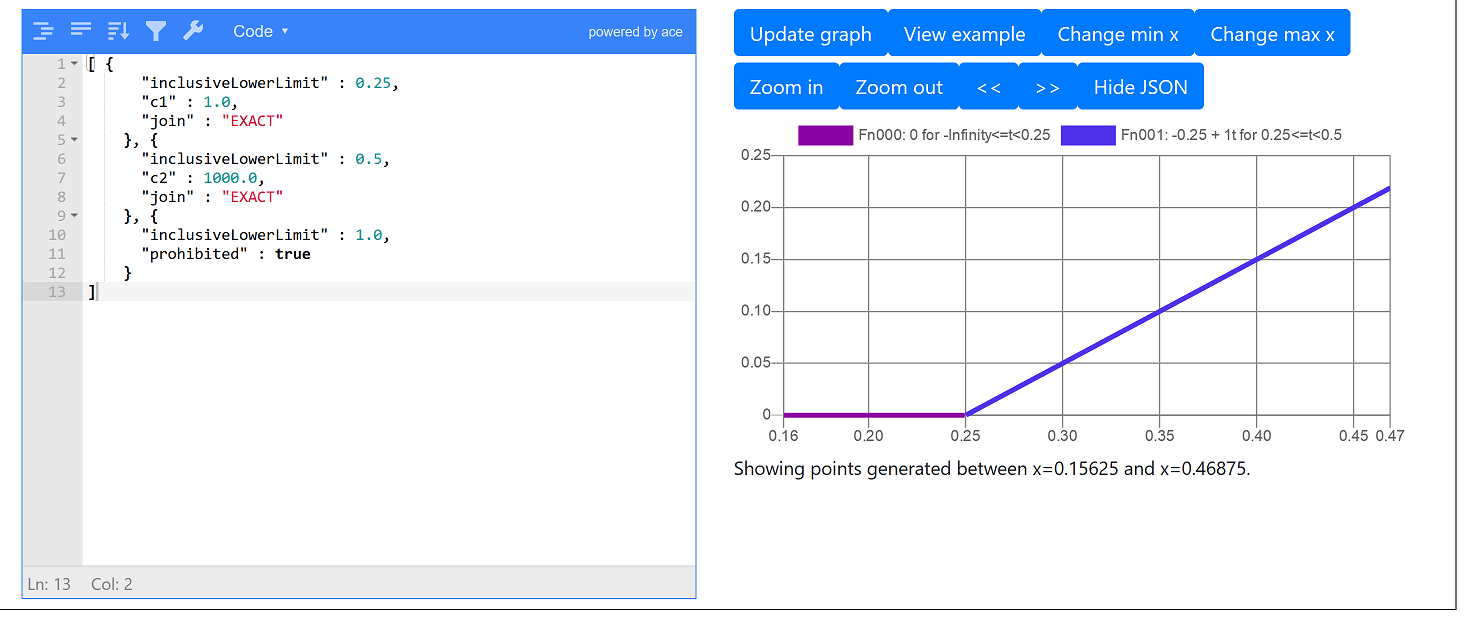
If the item is on-board between 0.25 hours and 0.5 hours, a linear penalty cost of 1 per hour is applied using the c1 constant. This appears as the blue line on the graph between x = 0.25 and x = 0.5. As the graph scales to the maximum visible y value, this blue line looks like it always has y = 0, however if you zoom in on just this blue line using the zoom buttons, you can see it’s actually increasing linearly (see later screenshot).
If the item is on-board between 0.5 and 1 hour, a much larger penalty is applied with c2 = 1000. This corresponds to the second array element in the hoursPenalty array and is shown as the second purple line on the graph which curves upwards. Using the c2 term (the per hour squared term) is important as it makes two jobs with on-board time of 40 minutes significantly less expensive than one job with an on-board time of say 80 minutes, and therefore makes the optimiser spread on-board time violation out across different jobs.
The item is not allowed to be on-board more than 1 hour (3rd element in the hoursPenalty array where prohibited=true, corresponding to the greyed out area on the graph).
The following image is the same graph but zoomed in on the first linear team, so you can see it’s actually linearly increasing:
If you’re scheduling in realtime you may want to omit the hard limit and but still keep the penalty terms. If a hard on-board limit cannot be met, the job will become unloaded from the solution even if it’s already on-board the vehicle. It is therefore better to always use soft limits for realtime scheduling and to manually intervene when the optimiser reports a high on-board penalty which cannot be reduced without canceling the order.
8.6.3 On-board limits based on direct travel time
You can also set on-board time limits based on the direct travel time between the pickup and delivery stops. For example, for a pickup-dropoff job with pickup location A and dropoff location B, you could set a limit such that the on-board time is no longer than 1.5 times the direct travel time from location A to location B. This is particularly relevant for ridesharing with passenger travel.
The travel time limit is calculated based on the estimated travel time at the time the vehicle departs from the pickup location. Let’s take an example where the direct travel time from A to B is 1.5 hours in rush hour but 1 hour outside of rush hour, and the limit is twice the direct travel time. If the pickup at A is done in rush hour the limit will be 1.5 × 2 = 3 hours but if the pickup is done outside of rush hour it will be 1 × 2 = 2 hours.
Three types of direct-based limit are supported - (1) a hard limit, (2) penalties in units of the travel time limit and (c) penalties in units of hours, where the function starts at the travel time limit.
You can combine the absolute-time limits defined in onboardTimePenalty.hoursPenalty with the direct travel time based limits defined in onboardTimePenalty.directTravelTimeBased (i.e. a job can have both).
You can enable detailed statistics in the reporting by setting the following field to true:
model.configuration.reporting.detailedStats4PlannedStopsWith detailed statistics on, an object called onboardTimeCalculationStats becomes available in each planned stop in the json plan. This object is a list (as with custom jobs a single stop can have several onboard limits) and each element in the list has the following fields:
directTravelTimeHours - the direct travel time from pickup to dropoff as calculated by the ODL Live engine at the time the vehicle leaves the pickup stop.
directBasedTimeLimitHours - the onboard travel limit calculated for this dropoff using the direct travel time.
hoursSincePickup - the total onboard hours.
hoursOverDirectBasedTimeLimit - the hours over the limit (so hoursOverDirectBasedTimeLimit = max(0, hoursSincePickup − directBasedTimeLimitHours).
These fields only appear for dropoff stops where the onboard limit is evaluated, they don’t appear under the pickup stops.
8.6.3.1 Hard direct travel time based limit
The following JSON job has a hard limit on the on-board time for a job of 1.75 times the direct travel time plus 10 minutes, where the 10 minutes is defined in hours (so it’s 10/60 = 0.167 hours):
{
"onboardTimePenalty" : {
"type" : "FROM_LEAVE_LOC",
"directTravelTimeBased" : {
"multiplyDirectTimeLimitBy" : 1.75,
"addHours2DirectTime" : 0.167,
"type" : "HARD_LIMIT"
}
},
"stops" : [ {
"type" : "SHIPMENT_PICKUP",
...
}, {
"type" : "SHIPMENT_DELIVERY",
...
} ],
"_id" : "job1"
}Note if you’re using the hard limit and you set multiplyDirectTimeLimitBy = 1 and addHours2DirectTime = 0 the job will likely not be loaded; instead leave a small tolerance to account for rounding errors internally, for example by setting addHours2DirectTime = 0.0001 or multiplyDirectTimeLimitBy = 1.0001.
8.6.3.2 Penalty functions in units of direct travel time based limit
Instead of using hard limits, you can also set penalty functions based on the on-board time relative to the direct travel time. This uses the same mathematical form of penalty functions as we used in the previous section, but the x parameter in the function is instead in units of the travel limit, not hours (where the travel limit is the direct travel time multiplied by multiplyDirectTimeLimitBy plus addHours2DirectTime).
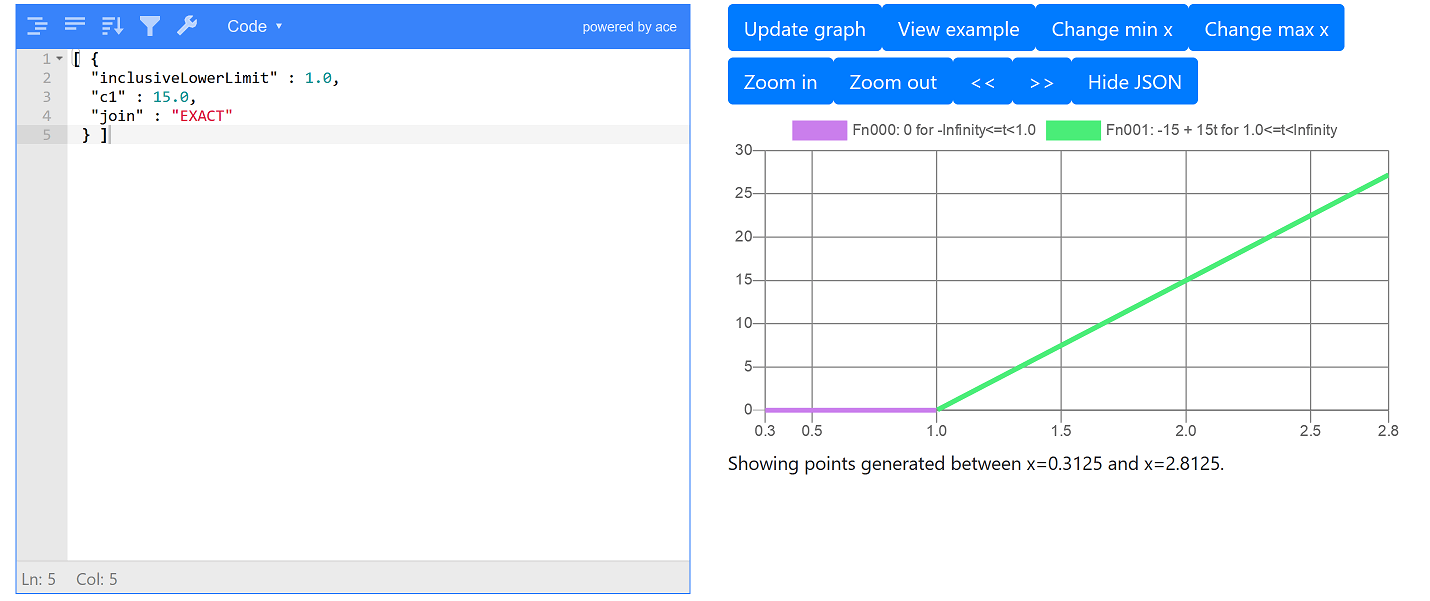
The following example job applies a penalty cost for the on-board time x which applies when x is 1 or more times greater than the direct travel time (this is defined by inclusiveLowerLimit). The penalty cost starts at 0 for x = 1 (i.e. on-board travel time is equal to the direct travel time) and then incurs a cost of 15 for each multiple of the direct travel time. For example, if the direct travel time is 20 minutes, the cost starts to be incurred at an on-board time of over 20 minutes, so the cost for 20 minutes on-board is 0, the cost for 40 minutes on-board is 15, for 60 minutes is 30 and for 80 minutes is 45.
{
"onboardTimePenalty" : {
"type" : "FROM_LEAVE_LOC",
"directTravelTimeBased" : {
"multiplyDirectTimeLimitBy" : 1,
"addHours2DirectTime" : 0,
"penalty" : [ {
"inclusiveLowerLimit" : 1.0,
"c1" : 15.0,
"join" : "EXACT"
} ],
"type" : "PENALTIES"
}
},
"stops" : [ {
"type" : "SHIPMENT_PICKUP",
...
}, {
"type" : "SHIPMENT_DELIVERY",
...
} ],
"_id" : "job1"
}The following screenshot shows the graph of this penalty function, using viewer tool in the developer’s dashboard (see section penalty functions for instructions):
8.6.3.3 Penalty functions in units of hours, function starts at the travel time limit
You can also set a penalty based on the number of hours onboard over the direct-based travel limit, by setting
directTravelTimeBased.type=HOURS_OVER_LIMIT_PENALTIESas shown in the following JSON:
{
"onboardTimePenalty" : {
"type" : "FROM_LEAVE_LOC",
"directTravelTimeBased" : {
"multiplyDirectTimeLimitBy": 1.5,
"addHours2DirectTime": 0.5,
"penalty": [
{
"inclusiveLowerLimit": 0.0,
"c0": 0.0, "c1": 0.0, "c2": 36000.0,
"join": "PLUS_CONST"
},
{
"inclusiveLowerLimit": 0.5,
"c0": 1000000.0, "c1": 0.0,"c2": 3.6E7,
"join": "PLUS_CONST"
}
],
"type": "HOURS_OVER_LIMIT_PENALTIES"
}
},
"stops" : [ ... ],
"_id" : "job1"
}The example model for non-emergency medical transportation in the following directory uses this type of penalty:
supporting-data-for-docs\example-models\next-day-non-emergency-patient-transportation-soft-rulesSee the readme.html in this directory for more details on this model.
8.6.4 Pickup time calculation options
For the field onboardTimePenalty.type we support the following values:
FROM_LEAVE_LOC. The on-board time is measured from the time we leave the location (where any two locations less than one metre away from each other are assumed to be the same location). Therefore if several pickups are made consecutively at the same location, and each pickup stop has a durationMillis defined, we measure the the on-board time from the time we complete the last pickup at the location.
FROM_PICKUP_TIME. The on-board time is measured from the time we pickup the item, not the time we leave the location.
8.6.5 Dropoff time calculation options
Warning
FROM_EARLIEST_POSSIBLE_SERVICE_TIME_FOR_COLOCATED_STOPS is not realtime compatible and will not be evaluated properly if you have dispatched stops.
By default, if stops A, B and C are all dropoffs happening consecutively at the same location (i.e. same latitude and longitude), the optimiser will do its time calculations as follows:
- Current time is t.
- Add parking time (if set) to t when the vehicle arrives at the location.
- Process stop A.
- Wait for A’s openTime, by setting t to the max of t and openTime.
- Set the dropoff time for A (used in the on-board calculation) to the current value of t.
- Add A’s durationMillis to t.
- Repeat step 3 for stop B instead.
- Repeat step 3 for stop C instead.
8.6.5.1 Consecutive service time option (default behaviour)
This option is the default behaviour and can be set explicitly using using the code:
FROM_CONSECUTIVE_SERVICE_TIME_FOR_COLOCATED_STOPS (default behaviour)Let’s assume durationMillis is 20 minutes for all stops. Stop’s B’s dropoff time for the on-board calculation will be calculated as at least 20 minutes after the vehicle arrives on-site and stop C’s dropoff time will be as at least 40 minutes after the vehicle arrives on-site.
8.6.5.2 Earliest possible service time option (using on-site arrival time instead)
In-reality, it may be more realistic to use a dropoff time which is the maximum of the stop’s openTime and the time the vehicle first arrived on-site. So for example, if (a) the vehicle arrived on-site at 9:00, (b) each dropoff has an openTime earlier than 9:00 and (c) durationMillis is 20 minutes for each, then the dropoff time used in the on-board calculation would be 9:00 for each stop, and then the vehicle would leave the location one hour later.
This option is set using the code:
FROM_EARLIEST_POSSIBLE_SERVICE_TIME_FOR_COLOCATED_STOPS8.6.5.3 Setting the options
You can control which of these options the optimiser uses by setting the field arrivalTimeLogicType in the on-board penalty structure.
Here we set arrivalTimeLogicType to
FROM_EARLIEST_POSSIBLE_SERVICE_TIME_FOR_COLOCATED_STOPSin the following JSON:
"onboardTimePenalty" : {
"type" : "FROM_LEAVE_LOC",
"hoursPenalty" : [ {
"inclusiveLowerLimit" : 1.0,
"prohibited" : true,
"join" : "EXACT"
} ],
"arrivalTimeLogicType" : "FROM_EARLIEST_POSSIBLE_SERVICE_TIME_FOR_COLOCATED_STOPS"
}Here we set it to
FROM_CONSECUTIVE_SERVICE_TIME_FOR_COLOCATED_STOPSinstead:
"onboardTimePenalty" : {
"type" : "FROM_LEAVE_LOC",
"hoursPenalty" : [ {
"inclusiveLowerLimit" : 1.0,
"prohibited" : true,
"join" : "EXACT"
} ],
"arrivalTimeLogicType" : "FROM_CONSECUTIVE_SERVICE_TIME_FOR_COLOCATED_STOPS"
}If you leave the field arrivalTimeLogicType out of the JSON, the default behaviour will be:
FROM_CONSECUTIVE_SERVICE_TIME_FOR_COLOCATED_STOPS8.6.5.4 Example models
In the directory:
supporting-data-for-docs\\example-models\\onboard-limit-arrival-time-logicwe have 2 example model JSONs:
default-logic-model.jsonand
model-using-FROM_EARLIEST_POSSIBLE_SERVICE_TIME_FOR_COLOCATED_STOPS.jsonThese jsons don’t use road network data, so you don’t need to set this up to run them. The models are identical except they use different values of arrivalTimeLogicType. Each model contains three pickup-dropoff jobs, with the same pickup location and the same dropoff location. Each job has a hard on-board limit of 1 hour with each dropoff taking 3 hours. For the first model using the default logic type, we get a route which is Pickup, Dropoff, Pickup, Dropoff, Pickup, Dropoff, because this is the only way the on-board time limit cannot be broken. For the second model, using:
FROM_EARLIEST_POSSIBLE_SERVICE_TIME_FOR_COLOCATED_STOPSwe instead get a route Pickup, Pickup, Pickup, Dropoff, Dropoff, Dropoff.
8.6.6 On-board time penalties for custom jobs
On-board penalties for custom jobs are defined in the field job.onboardTimePenalties which is a JSON array. Each element in the job.onboardTimePenalties array supports exactly the same fields as job.onboardTimePenalty, and so you can use onboardTimePenalties to define multiple penalties. For penalties defined in the onboardTimePenalties array, you must also set two additional fields startStopIds and endStopIds. These two extra fields are arrays of stop ids, which specify which stops in the jobs the on-board penalty acts between.
In the following example custom job JSON we show just one element in the job.onboardTimePenalties array. This element has one stop id defined in startStopIds and three stop ids in endStopIds which tells ODL Live to apply this penalty function three different times, acting from the stop with id “pickup” to (1) stop with id “dropoff1”, (2) stop with id “dropoff2” and (3) stop with id “dropoff3”.
{
"onboardTimePenalties" : [ {
"type" : "FROM_LEAVE_LOC",
"hoursPenalty" : [ {
"inclusiveLowerLimit" : 0.5,
"c1" : 100.0
} ],
"startStopIds" : [ "pickup" ],
"endStopIds" : [ "dropoff1", "dropoff2", "dropoff3" ]
} ],
"stops" : [ {
"type" : "CUSTOM",
"coordinate" : {"latitude" : 0.0, "longitude" : 0.0},
"relativeSequenceConstraint" : 0,
"_id" : "pickup"
}, {
"type" : "CUSTOM",
"coordinate" : {"latitude" : 0.0, "longitude" : 0.0},
"relativeSequenceConstraint" : 0,
"_id" : "dropoff1"
}, {
"type" : "CUSTOM",
"coordinate" : {"latitude" : 0.0, "longitude" : 0.0},
"relativeSequenceConstraint" : 0,
"_id" : "dropoff2"
}, {
"type" : "CUSTOM",
"coordinate" : {"latitude" : 0.0, "longitude" : 0.0},
"relativeSequenceConstraint" : 0,
"_id" : "dropoff3"
} ],
"_id" : "customJob1"
}8.6.7 Delayed pickups and time windows
If you’re using on-board penalties and the openTime of the delivery stop is significantly later than the openTime of the pickup stop (or the pickup stop has no openTime), it may be more efficient to delay the pickup (i.e. do the pickup stop later). For example, if a vehicle starts work at 8am, picks up an item at 8:10am, arrives at the item’s delivery stop at 8:20am but the delivery is not open until 9:00am, the item will have to be on-board for 50 minutes. This could result in large on-board penalty cost, or break a hard on-board limit (meaning the job would not be assigned). Delaying the pickup, by staying at the vehicle start location until 8:50am, would solve this issue.
For problems like these you should use during-optimisation delays, so the optimiser can calculate delayed pickup times when needed, and optimise correctly around these. Without using during-optimisation delays, jobs may be unassigned or the optimiser may choose inefficient routes simply because they delay a pickup and therefore minimise the on-board penalty.
8.7 Override distance profile when onboard
WARNING - overrideDistancesProfileIdWhenOnboard is not yet realtime compatible and will not give the correct behaviour if you have dispatched stops.
In ODL Live you can define multiple distance profile configurations,
which control the calculated driving distance, speed etc. between stops.
A vehicle will use the distances profile id defined in
vehicle.definition.distancesProfileId if defined, or the
default distances profile if undefined. Jobs can override the distances
profile used by the vehicle when they are onboard, by setting the field
job.overrideDistancesProfileIdWhenOnboard. This allows (for
example), you to set the vehicle to drive slower when certain items are
onboard. As different distances profiles can use different road network
graphs, you could have one road network built with roads the vehicle can
traverse on anytime, and another road network containing only the roads
the vehicle is allowed to travel on when certain items are on-board
(e.g. potentially dangerous chemicals). Alternatively you could use
different external travel time matrix files for different profiles.
We have an example model in the following directory:
supporting-data-for-docs\example-models\overriding-distances-profile-based-on-onboard-jobs\example-model.jsonHere’s a job from this example model which forces the vehicle to use
a distances profile with id ‘fast’ when it’s onboard by setting
job.overrideDistancesProfileIdWhenOnboard:
{
"quantities": [
100
],
"overrideDistancesProfileIdWhenOnboard": "fast",
"stops": [
{
"type": "SHIPMENT_PICKUP",
"coordinate": {
"latitude": -0.0031532074649807205,
"longitude": -0.0051985678615828835
},
"_id": "FastPick"
},
{
"type": "SHIPMENT_DELIVERY",
"coordinate": {
"latitude": -0.006169240712974335,
"longitude": 0.008406898115185845
},
"_id": "FastDrop"
}
],
"_id": "MakesStopsFastJob"
}We have another job in the example model which similarly forces the
vehicle to use a distance profile with id ‘slow’, and three more jobs
which don’t force the vehicle to use any specific profile. This is the
definition of the configuration.distances from the example
model:
"distances" : {
"type" : "EUCLID",
"days" : [ ],
"profiles" : {
"fast" : {
"type" : "EUCLID",
"straightLineSpeedMetresPerSec" : 2235.2,
"days" : [ ]
},
"slow" : {
"type" : "EUCLID",
"straightLineSpeedMetresPerSec" : 0.22352,
"days" : [ ]
}
}
}We’re using straight line distances here
(type = "EUCLUD") to keep things simple, but you can use
road network distances instead here (including standard speeds) or an
external matrix, just by replacing the JSON in each profile. If
straightLineSpeedMetresPerSec is not set in the profile, it
defaults to 22.352 metres per second (equivalent to 50 miles/hour). We
have three distances profiles here, the main profile (for which we can
only see the field "type" : "EUCLID" just below
"distances") and the fast and slow profiles. The fast and
slow profiles make the vehicle move 100x faster and 100x slower
respectively.
Here’s an example route we get when from optimising this model:
FastPick,Normal1Pick,Normal2Pick,Normal3Pick,Normal3Drop,Normal1Drop,Normal2Drop,FastDrop,SlowPick,SlowDropThe route you see when running yourself could be reversed (as both have the same cost), but should have the following properties:
All normal stops are done between the fast pickup stop and the fast dropoff stop.
There are no stops between the slow pickup stop and the slow dropoff stop.
We set (using quantities) that the fast and slow jobs couldn’t be onboard at the same time, to keep things simple. As it’s much quicker to do jobs when the fast job is onboard, the normal stops are done in between fast pickup and fast dropoff. As it’s much slower to do jobs when the slow job is onboard, no other jobs are served with the slow job onboard (i.e. between slop pickup and slow dropoff). This is exactly what we’d expect for this (somewhat artificial) problem.
If multiple jobs are onboard at once with different values of
overrideDistancesProfileIdWhenOnboard, the optimiser will
choose the one that’s most common, doing an arbitrary tiebreak if
needed.
8.8 Periodic routing problems
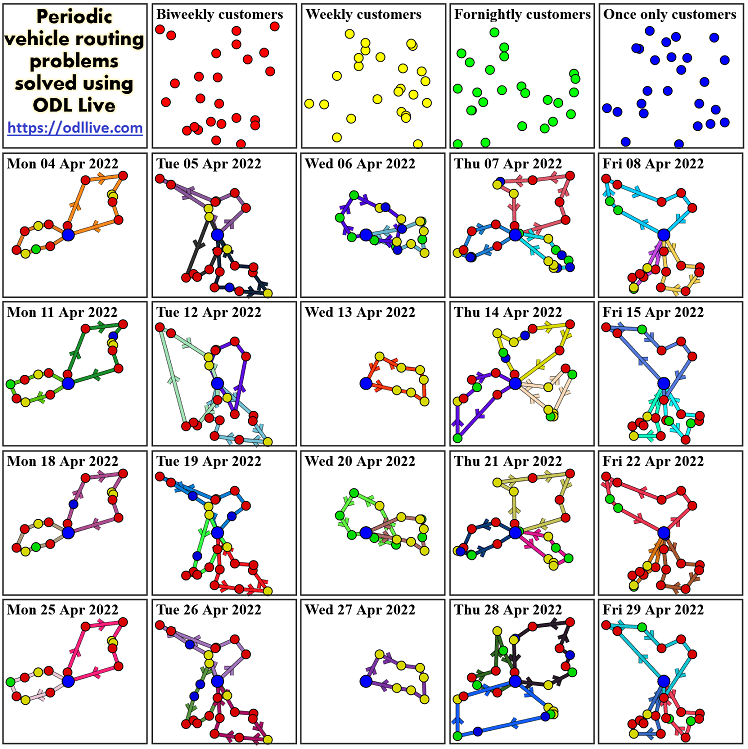
In periodic vehicle routing problems, customers (e.g. shops needing restocking) need regular deliveries at different frequencies. For each customer, the optimiser needs to (a) choose its first delivery start date, and (b) assign each delivery to a vehicle and position. The start date locks a customer into a pattern, e.g. if the first delivery to a weekly customer is on Monday, all following visits should also be on Monday. The picture below shows one of our test cases covering a four-week period. Customers are visited once only, fortnightly, weekly or biweekly. A biweekly can be visited either Monday+Thursday, or Tuesday+Friday - so if the first visit is Monday, all later visits are Monday and Thursday. On Tuesday 5th April the two biweeklys (coloured red) in the top left are served for the first time, and then served every Friday and Tuesday after that. Similarly, the fortnightly customer (green) on the left on Monday 11th April is next served on Monday 25th April and weekly customers (yellow) are served on the same day each week.
An example periodic problem is available in the supporting-data-for-docs directory:
supporting-data-for-docs\example-models\periodic\straight-lines-london-periodic.jsonThis model doesn’t use road networks so you don’t need to setup the road network data. Here’s an example job from straight-lines-london-periodic.json which repeats every week on the same day:
{
"altJobs": [
{
"stops": [{
"type": "DELIVER",
"durationMillis": 3600000,
"coordinate": {"latitude": 51.503339320182064,"longitude": -0.3232552120214237},
"openTime": "2022-04-04T08:00", "closeTime": "2022-04-04T16:00",
"_id": "Weekly5Day0"
}],
"_id": "Weekly5Day0"
},
{
"stops": [{
"type": "DELIVER",
"durationMillis": 3600000,
"coordinate": {"latitude": 51.503339320182064,"longitude": -0.3232552120214237},
"openTime": "2022-04-05T08:00", "closeTime": "2022-04-05T16:00",
"_id": "Weekly5Day1"
}],
"_id": "Weekly5Day1"
},
{
"stops": [{
"type": "DELIVER",
"durationMillis": 3600000,
"coordinate": {"latitude": 51.503339320182064,"longitude": -0.3232552120214237},
"openTime": "2022-04-06T08:00", "closeTime": "2022-04-06T16:00",
"_id": "Weekly5Day2"
}],
"_id": "Weekly5Day2"
},
{
"stops": [{
"type": "DELIVER",
"durationMillis": 3600000,
"coordinate": {"latitude": 51.503339320182064,"longitude": -0.3232552120214237},
"openTime": "2022-04-07T08:00", "closeTime": "2022-04-07T16:00",
"_id": "Weekly5Day3"
}],
"_id": "Weekly5Day3"
},
{
"stops": [{
"type": "DELIVER",
"durationMillis": 3600000,
"coordinate": {"latitude": 51.503339320182064,"longitude": -0.3232552120214237},
"openTime": "2022-04-08T08:00", "closeTime": "2022-04-08T16:00",
"_id": "Weekly5Day4"
}],
"_id": "Weekly5Day4"
}
],
"jobPatterns": [
{
"jobIds": ["Weekly5Day0"],
"repeatNTimes": 4,
"repeatUnit": "WEEK"
},
{
"jobIds": ["Weekly5Day1"],
"repeatNTimes": 4,
"repeatUnit": "WEEK"
},
{
"jobIds": ["Weekly5Day2"],
"repeatNTimes": 4,
"repeatUnit": "WEEK"
},
{
"jobIds": ["Weekly5Day3"],
"repeatNTimes": 4,
"repeatUnit": "WEEK"
},
{
"jobIds": ["Weekly5Day4"],
"repeatNTimes": 4,
"repeatUnit": "WEEK"
}
],
"_id": "Weekly5"
}In this job, in the altJobs array, we have 5 different versions of the job for the 5 different weekdays (Monday-Friday) in the first week the job is served. Each version in altJobs is the same apart from ids and open/close times. The job patterns have 2 new fields repeatNTimes and repeatUnit:
{
"jobIds": ["Weekly5Day1"],
"repeatNTimes": 4,
"repeatUnit": "WEEK"
}These fields tell the optimiser that the job should be repeated 4 times with a week between each repeat. The jobIds just contains one job id for this pattern, but this job will be copied from week 0 (the week defined in alt jobs) onto week 1, week 2 and week 3 because we repeat 4 times. These jobs will appear in the plan with the stop ids:
- Weekly5Day1~JPR_WEEK_0
- Weekly5Day1~JPR_WEEK_1
- Weekly5Day1~JPR_WEEK_2
- Weekly5Day1~JPR_WEEK_3
The optimiser adds ‘~JPR_X_Y’ to the stop id, where JPR stands for ‘job pattern repeat’, X is the repeatUnit and Y is the number of the repeat (e.g. repeat 0, repeat 1 etc).
The extra repeat fields which can be used in the pattern objects are:
- repeatNTimes. The number of times the job will be repeated.
- repeatUnit. The unit of time between each repeat. Allowed values are MONTH, FORTNIGHT, WEEK and DAY.
- repeatInterval. The number of time units between each repeat.
For example the following pattern will repeat 10 times with a 3 day gap between each repeat:
{
"jobIds": ["Weekly5Day1"],
"repeatNTimes": 10,
"repeatUnit": "DAY",
"repeatInterval": 3
}Although jobs can be defined to repeat, you must explicitly setup vehicle records for each day (i.e. the vehicle records currently have no ‘repeat’ option).
When the optimiser repeats a job, it considers daylight savings. All times are in the job (e.g. openTime) are defined in UTC not local time, however when the optimiser repeats the job, it (a) uses the stop coordinate to get the timezone for the job, (b) works out the local time from the UTC and (c) ensures the copied job has the same local time. So if you define a job in NYC to start at 13:00 UTC which is 9:00 NYC time, and when the job repeats it passes a daylight savings change (clocks going forward or back an hour), the repeated job will still start at 9:00 NYC, but this will appear as 12:00 or 14:00 UTC in the plan dependent on which way the clocks changed.
When looking at the map in the software developer’s dashboard, the URL parameter local-date can be used to filter for routes on a certain date in the local timezone, e.g. for straight-lines-london-periodic.json the following map URL will filter for the first date:
http://localhost:8080/experimental/dashboard/periodic/map?local-date=2022-04-04If you hit a date with no routes, you may see a blank page instead.
8.9 Preceeding enabler jobs (jobs that must follow others)
Using the from stop rules, you can setup a rule on a stop in a job A, that the stop can only be served directly after a different stop within a specific stop group, where this different stop could sit within a different job, e.g. job B. A real-life example of this could be if you were doing fuel delivery and you had a certain type of fuel which could only be delivered after another type of fuel. Let’s call job A the job that needs to be enabled (to make it feasible) and job B the enabler job, which must be placed directly before job A to make job A feasible. By default, the engine may have a hard time optimising this type of problem, because it won’t know that enabler job needs to go before job A. The preceeding enabler job logic solves this. It tells the optimiser that if a job couldn’t be placed in a position, because of a prohibited from stop rule, that the optimiser should try placing an enabler job directly before the first job. So for example, if you’re adding job A to a route, and both job A and job B are pickup-delivery jobs (i.e. job with 2 stops), the optimiser could try to insert as follows:
otherJob1, otherJob2, ..., pickup4JobB, delivery4JobB, pickup4JobA, otherJob3, otherJob4, ..., delivery4JobA Note that when the optimiser is trying to insert job B to enable job A, job B’s stops are placed in a row directly before job A, so there’s no stops from other jobs between pickup4JobB and delivery4JobB.
The following JSON shows an example of a job that needs to be enabled by another job (i.e. it shows an example of our job A). The job has a rule on its pickup stop that the stop must follow a stop in the stop group ‘appleStop’. It also has a job-level field preceedingEnablerJobGroupId which tells the optimiser that jobs in the job group ‘appleJob’ are its preceeding enabler jobs:
{
"preceedingEnablerJobGroupId": "appleJob",
"stops": [
{
"type": "SHIPMENT_PICKUP",
"coordinate": {
"latitude": 51.54504158503854,"longitude": -0.020518092601214677
},
"fromStopCosts": [
{
"fromStopGroupId": "appleStop",
"notFrom": true,
"prohibited": true
}
],
"_id": "pickup4JobA"
},
{
"type": "SHIPMENT_DELIVERY",
"coordinate": {
"latitude": 51.55320566085375,"longitude": -0.13089785947769422
},
"_id": "delivery4JobA"
}
],
"_id": "jobA"
}Next we show the job JSON for the enabler job (i.e. job B). It has a job-level field jobGroupIds which is an array and declares that the job is in the job group ‘appleJob’. Its delivery stop (which will be placed directly before job A’s pickup stop) is set to be in the stop group ‘appleStop’, which is the only type of stop that stop pickup4JobA (from the previous job) is allowed to follow:
{
"jobGroupIds": ["appleJob"],
"stops": [
{
"type": "SHIPMENT_PICKUP",
"coordinate": {
"latitude": 51.566292786316524,"longitude": 0.12829781850681776
},
"_id": "pickup4JobB"
},
{
"type": "SHIPMENT_DELIVERY",
"stopGroups": ["appleStop"],
"coordinate": {
"latitude": 51.52751302911337,"longitude": -0.24963874857181714
},
"_id": "delivery4JobB"
}
],
"_id": "jobB"
}Turning on the preceeding enabler job logic will slow down the optimiser, so you are recommended to restrict its use to smaller problems.
8.10 Reasons for jobs not loading
ODL Live will leave jobs unassigned if they cannot be assigned without breaking a hard constraint (e.g. violating vehicle capacity, the closeTime of a time window, etc). For unassigned jobs, ODL Live provides the likely reasons they’re unassigned, specifically it lists the hard constraint(s) that prevented them being assigned. For an unassigned job, ODL Live records all the hard constraints it encountered which preventing assigning the job to a particular vehicle or position on a vehicle. There are some caveats (i.e. ‘gotchas’) to be aware of:
If job A couldn’t be loaded onto vehicle X because of (a) quantity violations AND (b) time window violations, typically only the first violation ODL Live encountered will be reported - so you might have ‘quantities’ reported or ‘timeWindows’ but not both, even if both constraints need to be removed for job A to load.
If ODL Live reports that both ‘constraintA’ and ‘constraintB’ caused problems for a job, this could mean either (a) both ‘constraintA’ and ‘constraintB’ need removing or (b) the job would be assigned if either one of the constraints was removed. For example:
If job A couldn’t be loaded onto vehicle X because of quantity violations and couldn’t be loaded onto a different vehicle Y because of a time window violation, then you would see both ‘quantities’ and ‘timeWindows’ reported, although removing either quantities OR time windows would allow job A to be loaded. This same logic can also happen within a single route. If you had a pickup-delivery job which couldn’t fit on the first half of a route because of quantity contraints and then couldn’t fit onto the second half of the same route because of time window constraints, then removing the quantity or time window constraint would allow assignment.
If job A couldn’t fit onto vehicle X because (a) any further jobs added to the vehicle X would mean it returned home after its closeTime (i.e. time window violation) and (b) the quantity already being delivered by vehicle X meant it was full to capacity, then both ‘timeWindows’ and ‘quantities’ would need removing for the job to be assigned.
If you’re using some of ODL Live’s more advanced modelling features - e.g. replenishment routing or preceeding enabler job search, not load reasons may not be fully reported.
The not-load reasons are available in the plan under plan.unplannedAnalysis as shown in the following JSON:
{
"vehiclePlans": [
...
],
"statistics": {
...
},
"unplannedJobs": [
... unplanned jobs listed here
],
"unplannedAnalysis": [
{
"jobId": "j6",
"reasons": [
"quantities"
]
},
{
"jobId": "j8",
"reasons": [
"quantities","skills"
]
}
]
}You can also view these reasons for unassigned jobs using the software developer’s dashboard.
The following ‘constraint codes’ can appear in the plan.unplannedAnalysis[].reasons array:
depotId2PreventRevisitWithOnBoards - The depotId2PreventRevisitWithOnBoards rules prevented the job being loaded in one or more positions.
depotId4MultiTripRules - The depotId4MultiTripRules rules prevented the job being loaded in one or more positions.
doNotInsertAfterBreak - Normally occurs if a pickup-delivery job has breakAllowedBetweenStops set to false, so a position between a pickup and delivery of another job was rejected (see this section for more details).
finishLastJobTime - The job would break the hard latest finish job time for one or more vehicles.
futureNonBreakStopsLimit - Limit on the number of stops that can be assigned in a vehicle’s plan (independent of number of already dispatched stops).
invalidVehicleState - The vehicle record is corrupt in some way, for example it has preloaded stops with impossible time windows or a bad latitude and longitude on a dispatched stop or GPS trace.
logicLock - This occurs if a pickup in a pickup-delivery job is already dispatched to a vehicle, the ‘logicLock’ rule prevents the delivery being assigned to another vehicle. Vehicle job locks can also trigger this constaint code.
maxSeparation - At least one vehicle would have its hard maximum separation constraint broken if the job was assigned to it.
notReachable - Indicates that one stop is not reachable from another (where stop could also be the vehicle’s ‘depot’ stops). This could be due to:
- a bad latitude-longitude (e.g. stop in the middle of the sea),
- vehicles and jobs on different islands or continents,
- vehicles or stops outside of the area covered by the road network graph or
- a prohibited interstop rule preventing the route going from a stop in one stop group directly to a stop in another stop group.
noVehiclesOrAllClosed - Either no vehicles are available or the closeTime for all vehicles is before the current time.
onboardTime - One or more positions were rejected for the job as these would break the on-board time penalty of either the job or another job.
other - Code used when no other reason is available.
outOfOrderTWs - Job was not assigned to at least one position as the rule to prevent out-of-order time windows on a route is turned on, and it would have broken this rule. See section on enforcing lateness ordering.
placementRestriction - Job violated the placementRestriction on a stop in one or more possible positions.
planNotReady - Plan has not been generated yet (which could indicate corrupt input data in the model that’s creating an error).
quantities - One or more routes or positions were rejected for the job as it would violate the quantity constraints.
repositionTooLate - Related to predictive repositioning.
sequenceConstraint - One or more routes or positions were rejected for the job as they would violate the sequence constraint for the job or another job.
servePlusTravelLimit - The service plus travel hours limit has been broken.
serviceRadius - Job was found to break the hard service radius for one or more vehicles.
skills - One or more vehicles lacked the required skills for the job, or the job had skills which were prohibited for the vehicle.
stopGroupProperties - Most likely to occur if a vehicle overrides the fixed cost for a stop and sets it to infinite.
timeWindows - One or more routes or positions were rejected for the job as it would have created a time window violation. The violation could be for (a) the window on the job, or (b) the window on another job already on the route or (c) the return to depot time for the vehicle. See time windows section. Remember that ODL Live uses the current real-world time in its equations and so any job or vehicle with a closeTime in the past will not be schedulable unless you set the current time override to before the closeTime.
totalTravelHours - One or more routes were rejected as the job would have broken the route’s hard total travel hours limit, e.g. if the route was already full with other jobs.
totalTravelKm - One or more routes were rejected as the job would have broken the route’s hard total travel km limit.
vehicleLeftDepot - The vehicle has already left the depot, and therefore stops with type DELIVER can no longer be assigned to it. See this section for more details.
workTimeHours - One or more routes were rejected as the job would have broken their hard work time limit.
8.11 Required, prohibited and numeric skills
See skills section under vehicle features for more details on skills, which prohibit or allow a vehicle to serve a job. See the section on vehicle value-dependent cost functions for details of how to prohibit or allow a vehicle-job combination based on a vehicle’s numeric value (e.g. length, width).
Job-vehicle user functions can also be used to provide much more control on what combinations of jobs and vehicles are allowed.
8.12 Quantities
Each job can have a quantities array defined on it, as shown in the following delivery job:
{
"quantities": [
12,
1
],
"stops": [
{
"type": "DELIVER",
"durationMillis": 0,
"costFixed": 0,
"coordinate": {
"latitude": 51.5073,
"longitude": -0.1657
},
"_id": "stop1"
}
],
"_id": "job1"
}Each vehicle can have a corresponding capacities array defined on it, as shown in the following vehicle:
{
"definition": {
"start": { ... },
"end": { ... },
"capacities": [
100,
10
]
},
"_id": "vehicle1"
}The sum of quantity on-board a vehicle at any time must be less than vehicle’s corresponding capacity, where each capacity dimension is evaluated separately. You can define as many capacity dimensions as you want within reason (e.g. 3 or 5, but not 100). ODL Live doesn’t define what the quantity dimensions mean - they could be weight, volume, passengers etc but as far as ODL Live is concerned, they are just a number.
Quantities should be integer (i.e. whole numbers), a quantity value of 5.3 (for example), will just be treated as 5.
The real-time extension of the quantities model automatically takes care of items which have been picked-up along the route, providing (a) their job still exists in the model and (b) a record exists of their dispatch. Their quantity is auomatically removed from the vehicle’s available capacity.
Quantities can also be setup as soft constraints (that can be violated but this is penalised) and you can setup product mixing on-board rules by setting that certain quantity types cannot be on-board at once (called ‘incompatible quantities’).
8.12.1 Behaviour when dispatched jobs exceed the vehicle capacity
The quantities model copes with situations where a human planner has chosen to load deliveries onto a vehicle that exceed its defined capacity constraints (i.e. has created ‘impossible routes’ as far as the optimiser is concerned). For example, let’s imagine a pizza delivery bike can contain a maximum of 5 pizzas, but the human planner knows that for short journeys an extra pizza can be held (making a total of 6). The human planner therefore dispatches a 6-pizza order to the bike, as they know the delivery is only two minutes ride. The delivery is modelled as a shipment with two stops - (1) pickup pizza from restaurant, (2) deliver pizza to customer. The human planner dispatches the pickup to the bike knowing ODL Live will understand the order is now locked to that bike, and will automatically add the corresponding delivery stop to the planned route for the bike. ODL Live then detects that the capacity constraints are being overridden by the human planner and automatically adjusts them to ensure the delivery stop is still loaded onto the bike.
Crucially it only adjusts its capacity constraints when considering loading jobs that are locked to the vehicle, using either a shipment pickup’s dispatch or the deliveries locking mechanism detailed in later sections. Locking jobs to the vehicle in this manner is designed to model deliveries which have already been picked-up either from the depot or another location, are physically present on-board the vehicle, and therefore must be delivered. We illustrate this with a more complex example. Imagine you have 7 different orders, each going to a different location, for one pizza each. The bike’s capacity is still 5 pizzas and the 7 pickup stops have been manually dispatched to the bike by the human planner. The optimiser internally raises its capacity constraint to 7, to allow the delivery stops to be automatically planned for the dispatched pickup stops. However we do not want new jobs to be automatically planned on the bike’s route until its carrying only 4 pizzas, after making 3 deliveries, because the optimiser should still respect the standard capacity constraints. Therefore new jobs still need to use the standard constraints, but manually dispatched jobs need to use the adjusted constraints. ODL Live’s real-time extended quantities model correctly handles this situation.
8.13 Strict job priorities
strictOrderedAssignmentImportance allows you to
prioritise assigning one job over another job. The optimiser considers
strictOrderedAssignmentImportance before considering the cost model
(i.e. strictOrderedAssignmentImportance is more important than the cost
model). strictOrderedAssignmentImportance is an integer (i.e. whole)
number. The optimiser will prioritise assigning jobs with a larger
strictOrderedAssignmentImportance value first. It will prioritise
assigning just one job with a larger value of
strictOrderedAssignmentImportance over any number of jobs with a lower
value of strictOrderedAssignmentImportance, e.g. if job A has
strictOrderedAssignmentImportance=7, jobs B, C, D and E all
have strictOrderedAssignmentImportance=6 and the optimiser
can either fit A into a route or fit jobs B,C,D,E into a route, it will
assign A and leave jobs B,C,D,E unassigned. If instead you want to
prioritise jobs such that (for example) a high priority job is worth
three lower priority jobs, you should use the unassigned
cost.
strictOrderedAssignmentImportance should be in the range 0 to 1,000,000, numbers outside this range are clamped to within this range. So if you have a value of strictOrderedAssignmentImportance higher than 1,000,000, it will be treated as 1,000,000. If strictOrderedAssignmentImportance is 0 for a job, this logic is disabled for that job and the logic of assigning the job will instead be decided by the unassignedCost (if set). By default strictOrderedAssignmentImportance is 0 for a job if not set. Multiple jobs can have the same value of strictOrderedAssignmentImportance and they will be considered equally important.
The supporting-data-for-docs directory has an example model here:
example-models\strict-ordered-assignment-importance\strict-ordered-assignment-importance-example-model.jsonIn this model we have 30 DELIVER type jobs with a quantity of 1 each, and 3 vehicles with a total capacity of 10 across the vehicles. Only 10 jobs can therefore fit in. The jobs have ids j0, j1, …, j29 with corresponding stop ids s0, s1, …, s29. Job j0 has strictOrderedAssignmentImportance set to 0, j1 set to 1, j2 set to 2, …. , j29 to 29. Jobs with higher number ids are therefore more important than jobs with a lower number id. See the example job JSON below:
{
"quantities": [1],
"strictOrderedAssignmentImportance": 27,
"stops": [
{
"type": "DELIVER",
"coordinate": {
"latitude": 51.573237466240194,"longitude": -0.14687572745452154
},
"_id": "s27"
}
],
"_id": "j27"
}If you run this model, as only 10 jobs can fit in and the jobs with higher ids are more important, you will see that jobs j20, j21, …, j29 are all assigned to vehicles and all other jobs remain unassigned.
8.14 Unassigned cost / profits
If a job is unassigned (can’t be fitted into the plan), by default the optimiser considers the cost of this unassignment to be effectively infinite, and so it will minimise the number of unassigned jobs regardless of other costs.
The unassigned cost can model (a) situations where you have some jobs that are more important than others, and not all jobs can be assigned or (b) where you only want a profitable subset of jobs to be assigned (i.e. cherry-picking). High priority jobs can have a larger cost if they’re unassigned compared to low priority jobs. If instead you want to prioritise jobs such that one high priority job is more important than any number of lower priority jobs, you should use strictOrderedAssignmentImportance.
Consider the following example job JSON:
{
"stops" : [ {
"type" : "DELIVER",
"coordinate" : {
"latitude" : 51.511892,"longitude" : -0.123313
},
"multiTWs" : [ {
"openTime" : "2019-01-01T00:00",
"closeTime" : "2019-01-01T05:00",
"penalties" : [ {
"openTime" : "2019-01-01T00:00",
"closeTime" : "2019-01-01T05:00",
"cost" : 0.0,
"costPerHour" : 1000.0,
"costPerHourSqd" : 0.0
} ]
} ],
"_id" : "HighPriorityStop1"
} ],
"unassignedCost" : 10000.0,
"_id" : "HighPriorityJob1",
}We set the unassigned cost in the unassignedCost field of the job object. This job has a single time window which is open from 0:00 to 5:00 and it’s a high priority ‘ASAP’ job as it has an arrival time penalty function which starts at 0:00 and increases by 1000 cost per hour until the end time window 5:00. The optimiser will therefore try to schedule this job to start as close to its open time of 0:00 as much as possible, because for every hour after this a cost of 1000 is incurred. (See the section multiple time windows and custom lateness penalties for more information on how these penalty functions are setup).
Now imagine we have another job which is lower priority and therefore has an arrival time penalty costPerHour of 1 per hour instead:
{
"stops" : [ {
"type" : "DELIVER",
"coordinate" : {
"latitude" : 51.511892,"longitude" : -0.123313
},
"multiTWs" : [ {
"openTime" : "2019-01-01T00:00",
"closeTime" : "2019-01-01T05:00",
"penalties" : [ {
"openTime" : "2019-01-01T00:00",
"closeTime" : "2019-01-01T05:00",
"cost" : 0.0,
"costPerHour" : 1.0,
"costPerHourSqd" : 0.0
} ]
} ],
"_id" : "LowPriorityStop1"
} ],
"unassignedCost" : 10.0,
"_id" : "LowPriorityJob1",
}Ignoring the unassignedCost, if only one job can fit into the plan, and the earliest possible arrival time at the job is 1:00, from the arrival time penalty functions when the high priority job is served it will incur a penalty of 1000 but the low priority job will only incur a penalty of 1. Without considering unassignedCost, the optimiser will therefore think it’s cheaper (and therefore better) to serve the low priority job instead of the high priority job!
However when we consider unassignedCost as well, if we just served the low priority job we’d have a cost of 1 + 10, 000 = 10, 001 (as the low priority job has an arrival time penalty of 1 if it’s served at 1:00 and 10, 000 is the high priority job’s unassigned cost). Instead if we just served the high priority job we’d have a cost of 1, 000 + 1 = 1, 001. Serving the high priority job is therefore significantly cheaper than serving the low priority job when unassignedCost is used, and therefore the optimiser will make the right decision.
But how do you choose the unassigned cost?. The unassigned cost should be higher than the highest possible cost incurred if a job is served. The latest arrival time allowed at the job is 5:00 (from the closeTime of the time window). At 5:00 the high priority job will incur an arrival time penalty cost of 5 × 1, 000 = 5, 000 and the low priority job will incur one of 5 × 1 = 5. We’ve therefore set the unassignedCost to twice the maximum arrival time penalty for both jobs (10, 000 for the high priority job and 10 for the lower priority one). Setting the unassignedCost to twice the maximum cost that can be incurred by serving the job is a sensible rule to follow.
8.14.0.1 Extra heuristics for unassigned jobs
From ODL Live 1.5.16 onwards, by default the optimiser enables some extra special heuristics (i.e. search methods) for models with unassignedCost. These heuristics help the optimiser to search better when you have problems which involve cherry-picking a profitable subset of jobs to serve, instead of serving all jobs. They make the optimiser a little slower, so if you decide you don’t need them, you can de-activate these extra heuristics by setting model.data.configuration.optimiser.unassignedCost to DISABLED as follows:
{
"data": {},
"configuration": {
"optimiser": {
"unassignedCost": {
"optType": "DISABLED"
}
}
}
}8.15 Vehicle value-dependent costs
Job-vehicle user functions can be used instead of vehicle value-dependent cost functions if preferred, as these give more control.
Vehicle value-dependent cost functions let you set rules and costs on which vehicle can serve which job, based on numeric values of the vehicle.
A vehicle can contain named values like in the following vehicle JSON:
{
"definition" : {
"start" : {},
"end" : {},
"namedVals" : {
"x" : 2.0,
"y" : 4.0
}
},
"_id" : "v0"
}A job can have a field vehicleValCostFuncs which contains a map (i.e. a dictionary) of named values to general penalty functions like in the following job JSON:
{
"vehicleValCostFuncs" : {
"x" : [ {
"inclusiveLowerLimit" : "-Infinity",
"exclusiveUpperLimit" : 2.0,
"prohibited" : true
}, {
"inclusiveLowerLimit" : 6.0,
"exclusiveUpperLimit" : "Infinity",
"prohibited" : true
} ],
"y" : [ {
"inclusiveLowerLimit" : "-Infinity",
"exclusiveUpperLimit" : 4.0,
"prohibited" : true
}, {
"inclusiveLowerLimit" : 9.0,
"exclusiveUpperLimit" : "Infinity",
"prohibited" : true
} ]
},
"stops" : [ ],
"_id" : "j0"
}In this job JSON, we placed the following hard constraints on the vehicle values x and y:
2 ≤ x < 4
4 ≤ y < 9
The job will therefore only be assigned to the vehicle if both (a) the vehicle’s x value is between 2 and 4 and (b) the vehicle’s y value is between 4 and 9.
You can use this to model access constraints, for example if a stop cannot be accessed by a vehicle whose width is greater than 1.8 metres, you could set a named value of width on each vehicle, which defines its width, and a penalty function on the job which defines width must be less than 1.8:
[
{
"inclusiveLowerLimit": 1.8,
"prohibited": true
}
]If a named value referenced in vehicleValCostFuncs is not defined for a vehicle, its value is assumed to be 0.
As we’re using general penalty functions, you can also use them to define a cost based on these named values. For example, this vehicle JSON has a value baselineCostPerJob = 12 defined:
{
"definition" : {
"start" : { },
"end" : { },
"namedVals" : {
"baselineCostPerJob" : 12.0
},
"_id" : "v1"
}This job JSON has a rule that when it’s assigned to a vehicle, it will cost 1.5 times the vehicle’s baselineCostPerJob value:
{
"vehicleValCostFuncs" : {
"baselineCostPerJob" : [ {
"inclusiveLowerLimit" : 0.0,
"c1" : 1.5
} ]
},
"stops" : [ ],
"_id" : "j1"
}8.16 Wrong direction rule for trip fairness
8.16.1 Background
Designing efficient routes for transporting passengers can often have multiple conflicting aims or goals. One pair of conflicting goals arises when (a) you want to minimise the total on-board time for all passengers and (b) you don’t want any passenger to feel that they’ve been unfairly treated compared to the other passengers. This can happen if multiple passengers have the same dropoff location (e.g. airport, medical facility or school), you have a cluster of multiple pickup passengers far from the dropoff location and an isolated passenger pickup near to the dropoff location. If you’re purely minimising total on-board time, it actually makes ‘sense’ to pickup the isolated passenger first and then drive in the ‘wrong direction’ (as far as they’re concerned) further away from the dropoff to pickup the cluster of multiple passengers. This will minimise the objective function of the optimiser, but also annoy the isolated passenger, so clearly we need to modify the objective function.
There are a number of different possible ways to fix this behaviour (including using a squared power term on the on-board time penalty function), the ‘wrong direction rule’ is a simple approach which requires little or no tuning.
8.16.2 How the rule works
The wrong direction rule places a hard limit on the distance (measured along the roads) the driver can drive in the ‘wrong direction’ (i.e. away from the passenger’s dropoff location) after picking up a passenger. If the limit is set to zero, the rule prevents the vehicle from visiting any stop while the passenger is on-board which is further away from the dropoff than the passenger’s original pickup location.
If you’re using straight line distances, a zero limit basically means that once a passenger is picked-up, the vehicle can only visit stops within a circle which has its centre at the passenger dropoff location and the passenger pickup location on the circle’s circumference. The circle radius is therefore the driving distance from the passenger’s pickup to dropoff. In other words, the vehicle can only go ‘inwards’ towards the dropoff location.
We advise trying a limit of say 1 km or 10% of the direct driving distance, and reducing further down to 0 km as needed.
8.16.3 JSON format
The wrong direction rule should be defined on the pickup stop for a passenger transportation job. An array object called wrongDirectionRules should be placed on the picked stop, with an element inside of it as shown in the following pickup-dropoff job JSON:
{
"stops": [
{
"type": "SHIPMENT_PICKUP",
"coordinate": {
"latitude": 0.05328886565754135,"longitude": -51.108358509794996
},
"wrongDirectionRules": [
{
"evaluate2StopId": "D0",
"maxFurtherAwayKmFunction": [
{
"inclusiveLowerLimit": 0.0,
"c0": 2.0
}
]
}
],
"_id": "P0"
},
{
"type": "SHIPMENT_DELIVERY",
"coordinate": {
"latitude": 0.012476303844132544,"longitude": -51.07324996767547
},
"_id": "D0"
}
],
"_id": "Job1"
}The element should have a field evaluate2StopId which contains the _id of the dropoff stop. Explicitly setting the dropoff stop means that we can use the wrongDirectionRules for custom jobs which might have more than two stops.
The maxFurtherAwayKmFunction has the same structure as penalties function (technically a piecewise quadtratic function), except it doesn’t define a cost, it defines the ‘wrong direction’ hard limit. This json sets a 2km hard limit in the wrong direction, because the constant value c0=2:
"maxFurtherAwayKmFunction": [
{
"inclusiveLowerLimit": 0.0,
"c0": 2.0
}
]This example sets a hard limit of 3km + 25% of the direct travel distance between the pickup and the dropoff stop, because the constant c0=3 and the term c1 which gets multiplied by the direct travel distance is 0.25:
"maxFurtherAwayKmFunction": [
{
"inclusiveLowerLimit": 0.0,
"c0": 3.0,
"c1": 0.25,
}
]For this example, if the direct distance between the pickup and dropoff is 7km, the driver would be able to go a maximum of 3 + 0.25 × 7 = 4.75 km in the ‘wrong direction’ after doing the pickup.
8.16.4 Example rule
The supporting-data-for-docs directory has an example model in the following subdirectory:
supporting-data-for-docs\example-models\wrong-direction-ruleIn this model we have 5 jobs with an on-board penalty set so that we’re minimising the sum of on-board time for all jobs. All jobs have the same dropoff location and we use an additional constraint to force that the dropoff stops must be together at the end of the route. With rule off, one of the passengers near to the dropoff location actually gets picked-up first (because this minimises the total on-board time of all passengers) and then has to spend a long time on-board compared to the other passengers. With the rule on, this passenger is the second-last passenger picked-up instead and spends less time on-board, giving a fairer route.